
2025년 5월 29일, Black Forest Labs(BFL)에서 이미지 생성 및 편집이 가능한 새로운 인공지능 모델인 Flux.1 Kontext를 발표했습니다. 특히 텍스트의 정확성 및 시각적 창의성을 조화시키기 위해 설계된 Flux.1 Kontext는 AI를 사용한 시각적 생성 도구를 고도화하는 것을 목표로 하고 있습니다.
현재 오픈소스인 Flux.1 Kontext(dev)는 클로즈드 베타로 공개하고 있으며, Kontext자체는 여러 파트너 플랫폼 및 무료 데모 사이트를 통해 사용할 수 있으며, 이미지 생성형 인공 지능 모델에 새로운 이정표를 만들고 있습니다.
아래는 BFL의 공지에 포함된 이미지입니다. 아마도 왼쪽에 있는 이미지를 오른쪽처럼 편집할 수 있다는 것 같네요.

Flux.1 Kontext는 Text-to-Image 리더보드에서 6위를 차지하고 있습니다. 구글 Imagen 4에 약간 밀리고 있네요.
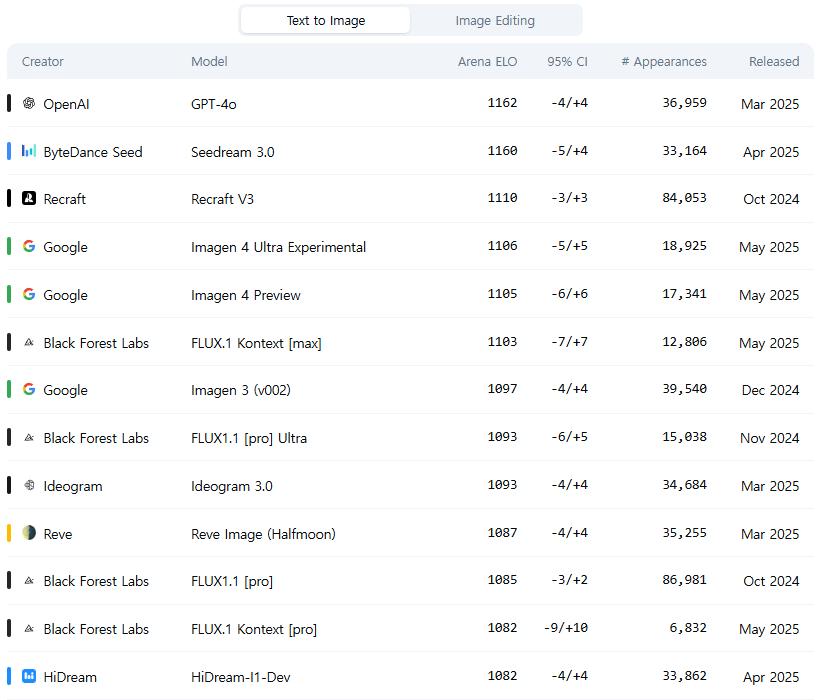
그런데 최근에 등장한 Image Editing 리더보드에서는 GPT-4o 에 이어 2등을 차지하고 있습니다. (단, 이 리더보드는 미드저니나 Imagen 4 등이 빠져 있어 완전하지는 않네요)

문맥을 따르는 이미지 생성
이미지 생성 커뮤니티에서 널리 사용되고 있는 Flux 모델을 개발한 Black Forest Labs에서는 FLUX.1 Kontext로 새로운 혁신을 선보였습니다. FLUX.1 Kontext 는 텍스트와 이미지를 입력받아 새로운 이미지 생성하거나, 변형할 수 있습니다. 즉, Kontext는 이미지 생성과 편집 기능을 하나의 모델로 통합한 모델입니다.
이러한 문맥 기반의 기능을 사용하면, 기존의 이미지에 존재하는 어떤 요소를 텍스트 명령만으로 변형할 수 있습니다. 이때 이미지의 피사체와 스타일은 그대로 유지됩니다. 아래는 BFL 공지에 나온 이미지에서 캡션을 번역한 것 입니다.

FLUX.1 Kontext 모델의 종류
FLUX.1 Kontext는 세가지 버전으로 발표되었습니다.
- Kontext [pro] : 빠르고 부드러운 편집을 위한 핵심 버전. 텍스트 기반의 생성, 이미지 기반의 편집, 스타일 복제 등을 하나의 통합된 프레임워크에서 수행할 수 있음. 대화식 워크플로에 적합
- Kontext [max] : 성능을 위주로 한 버전. 프롬프트의 이해도가 더 높고, 이미지내의 텍스트 처리가 더 정확한 버전. 특히 전문적인 용도에 적합
- Kontext [dev] : 클로즈드 베타 단계의 오픈 소스 버전. 맞춤화 및 기능 개발을 위한 목적. 상용 버전에 비해 기능은 약하지만, 오픈 소스 생태계에 새로운 솔루션이 될 것으로 기대함
기능
FLUX.1 Kontext의 기능은 다음과 같습니다.
- 국부적인 편집 : 이미지 전체는 변경하지 않고 원하는 부분만 편집
- 캐릭터 일관성 : 여러 이미지에 걸쳐 피사체의 특징 및 식별성을 유지
- 참조 이미지를 사용한 스타일 복제 : 참조 이미지에 정의된 시각적 스타일을 적용
- 이미지에 텍스트 삽입 : 시각적으로 문맥에 맞도록 텍스트를 생성
- 속도 : 평균 3-5분 정도에 추론. 미드저니등 경쟁 모델에 비해 최대 8배 빠름
이러한 기능은 다양한 용도로 활용될 수 있습니다. 일관성있는 아바타를 생성하거나, 프로토타입을 빠른 생성하고, 동질적인 일러스트레이션을 여러 장 생성하거나 웹 혹은 모바일 응용에서 이미지를 실시간으로 맞춤화하는 등이 그러한 예입니다.
  |
  |
사용 방법
FLUX.1 Kontext 가 발표된 후, 이미 Replicate, KreaAI, Freepik, Leonardo AI, Lightricks, OpenArt, Runway, FAL, Together AI등 수 많은 플랫폼에 통합되었습니다.
API 혹은 웹 인터페이스를 통해 접근할 수 있으며, 대부분 무료 시험 옵션(예: BFL Playground에서는 200 크레딧)을 제공해주고 있습니다.
아울러 베타 테스트가 완료된 후, HuggingFace 및 ComfyUI를 통해 오픈소스인 Kontext [dev] 도 공개할 예정입니다.
긍정적인 반응
X, Reddit 등 여러가지 소셜 미디어 및 포럼에서 Kontext 에 대한 렌더링 품질, 명령에 대해 따르는 정도, 특히 생성 횟수가 늘어나면서 얼마나 캐릭터 일관성이 유지되는지 등에 대한 토론이 이루어지고 있습니다. 그중 일부 사용자들은 ChatGPT에 통합된 OpenAI 이미지 모델보다 더 빠르고 유연하다며 호감을 표시하고 있습니다.
사용한 예에 따르면 디테일은 유지하면서도 캐릭터 이전이나 스타일 변경, 배경 변경 등이 성공적으로 이루어짐을 알 수 있습니다. 시각적 제어를 유지하면서도 복잡한 명령을 따르는 능력은 AI 이미지 편집에서 새로운 이정표를 마련한 것으로 보입니다.
이상입니다.
이 글은 stablediffuision.blog의 글을 참고로하여 작성했습니다.
민, 푸른하늘