2023년 11월 21일, 스테이블 디퓨전 개발사인 Stability.AI에서 비디오를 생성할 수 있는 스테이블 디퓨전 모델인 Stable Video Diffusion을 공개했습니다. 현재는 IMG2VID, 즉 이미지를 입력하면 그 이미지를 14프레임 또는 25프레임의 짧은 비디오만 생성되는 수준으로서, 텍스트 입력이 불가능하니 움직임을 제어하는 것은 불가능한 상태입니다. 거의... AnimateDiff에서 지원하는 정도라고 보시면 될 것 같네요.
이마저도 연구용으로만 제공되며, Stability.ai에서 제공하는 공식 샘플 사이트라고 할 수 있는 ClipDrip에서도 지원을 하지 않기 때문에 일반 사용자들은 AUTOMATIC1111 이나 ComfyUI에서 지원될 때까지는 사용할 수 없을 것 같습니다. 이런 웹UI는 이미지 생성형이기 때문에 별도의 서비스가 개발될 수도 있고요.
참고로 여기에 대기자로 등록하면, 나중에 text-to-video 기능을 최우선으로 사용할 수 있나봅니다.
아래는 보도자료를 번역한 내용입니다.
===
오늘 Stability AI에서는 이미지 생성 모델인 스테이블 디퓨전(Stable Diffusion)을 기반으로 생성형 비디오를 위한 첫 번째 기반 모델인 스테이블 비디오 디퓨전(SVD, Stable Video Diffusion)을 출시합니다.
현재는 연구용 프리뷰 버전으로만 제공되지만, 이 최첨단 생성형 AI 비디오 모델은 다양한 사용자를 위한 모델을 생성하고자하는 우리의 여정에서 매우 중요한 단계입니다.
이번 연구용 버전 공개에서는, 스테이블 비디오 디퓨전을 위한 코드는 GitHub 저장소에서 사용할 수 있으며, 로컬에서 모델을 실행하는 데 필요한 가중치는 Hugging Face 페이지에서 확인할 수 있습니다. 모델의 기술적 기능에 대한 자세한 내용은 연구 논문에서 확인할 수 있습니다.
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.
다양한 비디오 응용에서 적용 가능
스테이블 디퓨전 비디오 모델은 멀티뷰 데이터 세트에 대한 미세 조정을 통해, 단일 이미지로부터 멀티뷰 합성을 비롯한 다양한 다운스트림 작업에 쉽게 적용 수 있습니다. Stability.ai에서는 스테이블 디퓨전을 중심으로 구축된 생태계와 유사하게, 이 기반 비디오 메델을 바탕으로 하고, 더욱 확장하는 다양한 모델을 계획하고 있습니다.
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.
또한, 오늘부터 여기에서 대기자 명단에 등록하면, 곧 출시될 텍스트-투-비디오 인터페이스를 갖춘 새로운 웹 환경에 접근하실 수 있습니다. 이 도구는 광고, 교육, 엔터테인먼트 등 다양한 분야에서 비디오용 스테이블 디퓨전의 실제 적용 사례를 보여줍니다.
성능 비교
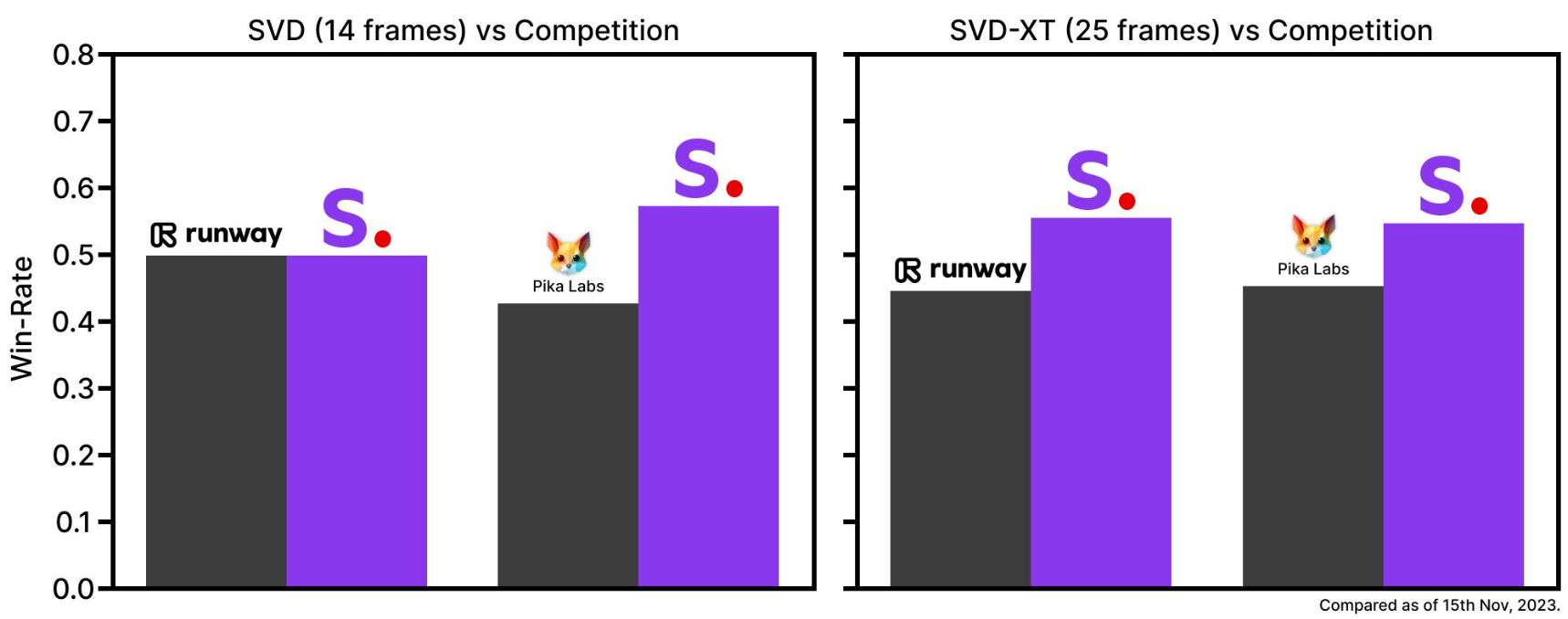
비디오 생성 스테이블 디퓨전은 사용자 지정 가능한 프레임 속도 (초당 3~30프레임 사이) 로 총 14프레임 또는 25프레임을 생성할 수 있는 두 가지 이미지-비디오 모델 형태로 출시되었습니다. 현재의 기본 형태에 대해 외부 평가를 수행한 결과, 이 모델들이 사용자 선호도 조사에서 주요 폐쇄형 모델을 능가하는 것으로 나타났습니다.
연구 전용
최신의 발전 사항에 맞춰 이 모델을 열심히 업데이트하면서 여러분의 피드백을 반영하기 위해 노력하고 있지만, 현재 단계에서는 실용 혹은 상업용 응용을 위한 것이 아니라는 점을 강조합니다. 안전과 품질에 대한 사용자 여러분의 아이디어와 피드백은 이 모델을 개선하여 최종 출시하는 데 매우 중요합니다.
이는 이전 제품 공개에서와 마찬가지로서, 조만간 여러분께 완전히 공개할 수 있기를 기대합니다.
계속 확장되는 AI 모델 제품군
비디오 생성 스테이블 디퓨전은 우리 회사가 보유한 다양한 오픈 소스 모델에 새로이 추가된 자랑스러운 제품입니다. 이미지, 언어, 오디오, 3D, 코드 등 다양한 형태를 아우르는 이 포트폴리오는 인간의 지능을 증폭시키기 위한 Stability AI의 헌신이라고 다짐합니다.
====
스테이블 비디오 디퓨전 모델 카드 (https://huggingface.co/stabilityai/stable-video-diffusion-img2vid)
비디오 생성 스테이블 디퓨전(SVD, Stable Video Diffusion) image-to-video는 정지 이미지를 조건부여(conditioning) 프레임으로 사용하여, 이로부터 비디오를 생성하는 확산 모델입니다.
모델 세부 정보
모델 설명
(SVD) 이미지-투-비디오는 이미지 조건부여(conditioning)으로부터 짧은 비디오 클립을 생성하도록 훈련된 잠재 확산 모델(latent diffusion model)입니다. 이 모델은 해상도 576x1024 크기의 컨텍스트 프레임이 주어지면, 동일한 크기의 14개의 비디오 프레임을 생성하도록 훈련되었습니다. 또한 시간적 일관성을 유지하기 위해 널리 사용되는 f8 디코더를 미세 조정했습니다. 편의를 위해 우리는 모델에 표준 프레임별 디코더를 추가로 제공합니다(여기).
모델 출처
연구 목적으로는 가장 널리 활용되고 있는 디퓨전 프레임워크(훈련 및 추론 모두)를 구현하는 Github 저장소(https://github.com/Stability-AI/generative-models)의 생성 모델을 사용하기를 권장합니다.
저장소: https://github.com/Stability-AI/generative-models
논문: https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
평가

위 차트는 기존의 GEN-2 및 PikaLabs에 대한 SVD-Image-to-Video의 사용자 선호도를 평가한 것입니다. 비디오 품질 측면에서 SVD-Image-to-Video가 더 선호되는 것으로 나타났습니다. 사용자 연구에 대한 자세한 내용은 연구 논문을 참조하세요.
사용 제한
직접 사용
이 모델은 연구 목적으로만 제공됩니다. 가능한 연구 분야 및 작업은 다음과 같습니다.
- 생성형 모델에 대한 연구.
- 유해한 콘텐츠를 생성할 가능성이 있는 모델의 안전한 배포.
- 생성 모델의 한계와 편견에 대한 조사 및 이해.
- 예술 작품의 생성 및 디자인 및 기타 예술적 프로세스에 사용.
- 교육 또는 창작 도구에 활용.
범위 외 사용
이 모델은 사람이나 사건을 사실적으로 표현하도록 학습되지 않았으므로 이러한 콘텐츠를 생성하는 것은 이 모델의 능력 범위를 벗어나는 것입니다. 이 모델은 Stability AI의 사용 제한 정책을 위반하는 방식으로 사용해서는 안 됩니다.