요즘 누구나 쉽게 인공지능 이미지를 생성할 수 있는 환경이 되었습니다. 특히 ChatGPT에 GTP-4o가 채택되면서 이미지 생성기능이 대폭 강화되어서, 프롬프트만 잘 입력하면(심지어는 한글로도) 아무 신경쓰지 않고도 정말 품질이 좋은 이미지를 생성할 수 있게 되었습니다.
그러다 보니, 어디에서나 쉽게 인공지능 이미지를 만날 수 있게 되었습니다. 가끔 멋진 이미지를 만나면(구지 인공지능 이미지가 아닌 실사 이미지도 마찬가지입니다), 비슷한 이미지를 생성해보고 싶다는 생각을 할 때가 있습니다. 이럴 때는 먼저 이미지로부터 프롬프트를 추출한 뒤, 이를 다른 인공지능 모델 또는 서비스에 입력하면 유사한 이미지를 생성할 수 있습니다. 참고로 저는 이미지에서 프롬프트를 추출할 때, JoyCaption 사이트를 많이 사용합니다.
그런데, 구지 이런 과정을 거칠 필요 없이, 한꺼번에 처리해줄 수도 있습니다. 또한 아래 우측과 같이 프롬프트에 새로운 내용을 추가해 다른 분위기를 만들 수도 있습니다. 이 글에서는 이러한 워크플로를 소개합니다.
 |
 |
 |
소프트웨어
이 글에서는 스테이블 디퓨전용 GUI중에서도 제일 강력하며, 현재 거의 대세로 자리잡고 있는 ComfyUI를 사용합니다. ComfyUI가 처음이시라면, 설치 및 기본 사용방법 및 초보가이드를 확인하시기 바랍니다.
워크플로 작동 원리
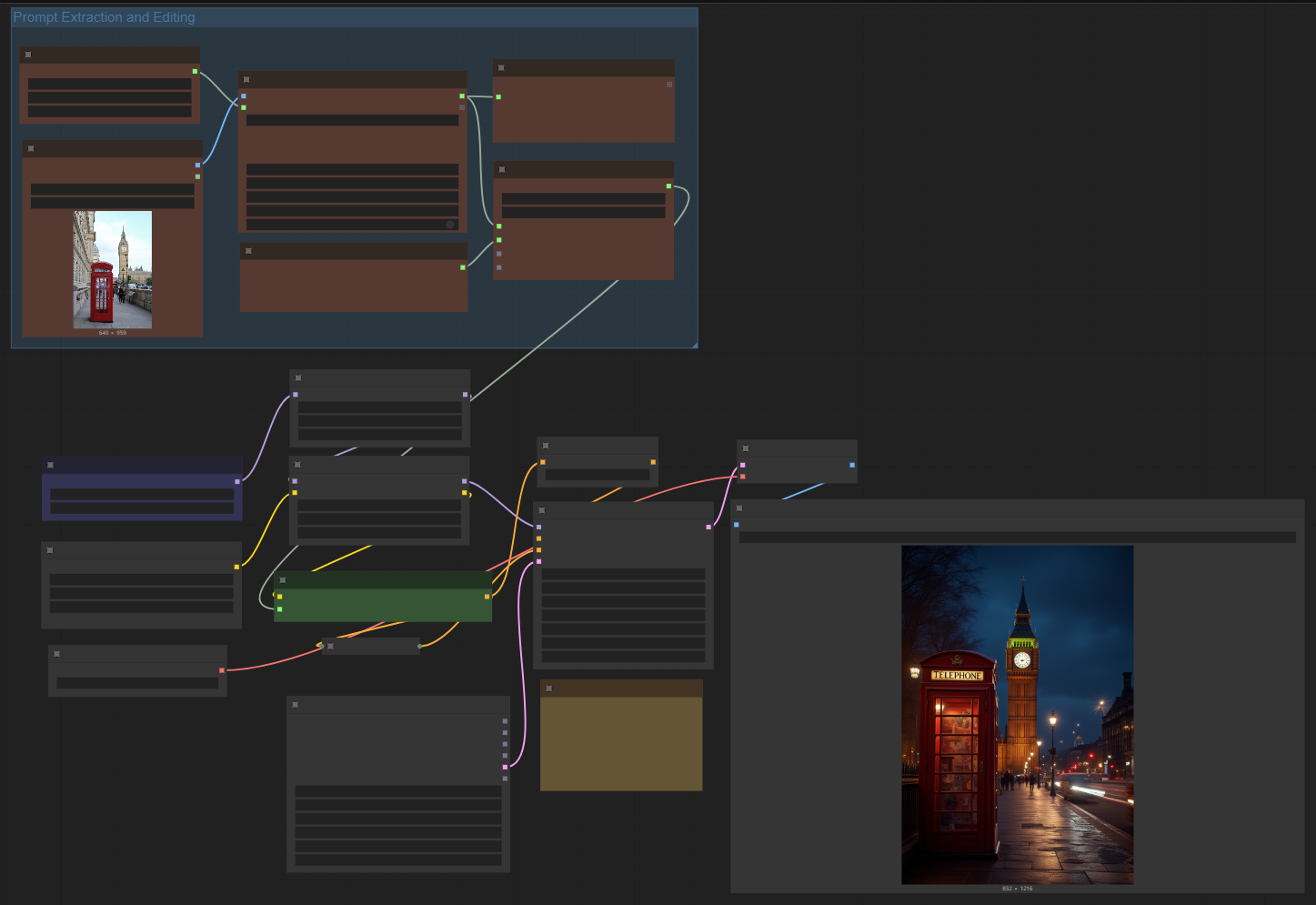
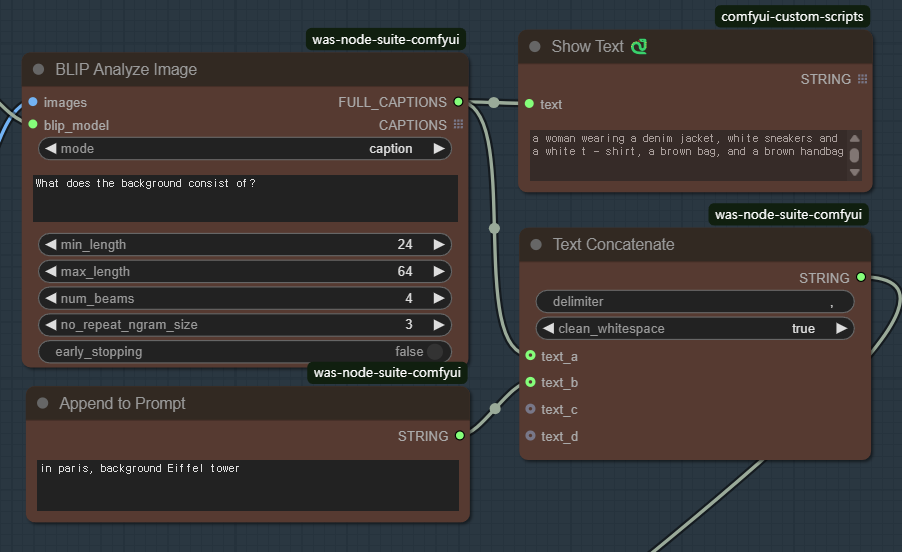
이 워크플로에선는 BLIP visual 모델을 사용하여 입력된 이미지의 프롬프트를 추출합니다.

[BLIP Analyze Image] 노드는 입력받은 이미지를 BLIP 모델로 해석하여 텍스트로 전환합니다. 여기에 필요할 경우 [Append to Prompt]노드에 원하는 내용을 입력하면, 이 두가지 텍스트를 합쳐서 프롬프트로 사용하게 됩니다.
따라하기
1 단계: 모델 다운로드
이 워크플로에서는 flux1-dev.sft 모델을 사용합니다. 이 파일을 다운로드 받은 후, ComfyUI\models\unet 또는 ComfyUI\models\diffusion_models 에 넣어줍니다.
텍스트 인코더 모델 clip_l.safetensors 및 t5xxl_fp16.safetensors을 다운로드 받은 후, ComfyUI\models\clip 폴더에 넣어줍니다.
VAE 모델 ae.safetensors 을 다운로드 받은 후, ComfyUI\models\VAE 폴더에 넣어줍니다.
2 단계: 워크플로 불러오기
아래의 Json 파일을 다운로드 받아 ComfyUI로 불러옵니다.
이 워크플로를 불러오면 오류가 발생할 수 있습니다. 그러한 경우, 다음과 같은 작업이 필요합니다.
- 처음 사용할 때 - ComfyUI Manager 를 설치해야 합니다.
- ComfyUI를 오랜만에 사용할 때 - ComfyUI를 최신버전으로 업데이트해야 합니다.
- 노드가 없다고 (빨간색) 경고가 뜰 때 - 빠진 커스톰 노드를 가져오기해야 합니다.
- 불러오기 혹은 수행중 에러 발생시 - 커스톰 노드를 업데이트해야 합니다.
3 단계: 이미지 설정
아래와 같이 비디오 첫 프레임으로 사용할 이미지를 선택합니다. 아래의 이미지를 사용하셔도 됩니다.

{kind=link}
4 단계: 이미지 생성
이제 [Queue] 버튼을 누르면 이미지가 생성됩니다.

5단계: 프롬프트 변경
이 워크플로를 실행시키면 아래 이미지의 [Show Text] 노드에 현재 불러온 이미지에서 추출한 프롬프트가 나타납니다. 이때, [Append to Prompt] 노드에 적당한 내용을 입력하면, 이 두 가지 내용이 합쳐져서 이미지가 생성됩니다.
추출된 텍스트: a woman wearing a denim jacket, white sneakers and a white T-shirt, a brown bag, and a brown handbag
추가한 텍스트: in Paris, background Effiel tower
아래는 그 결과입니다.
 |
 |
이상입니다.
이 글은 stable-diffusion-art.com의 글을 참고하여 작성하였습니다.