제가 요즘 제일 많이 사용하는 stable diffusion용 웹 UI는 ComfyUI입니다. 처음 사용하기는 까다롭지만, 일단 원하는 대로 설정하면 사용하기가 편하기 때문입니다. 그래서 글을 몇개 쓰기는 했는데, 그다지 마음에 들지는 않았습니다. 그러던 차에 제가 구독하는 stable-diffusion-art.com에서 ComfyUI 소개글이 나와서 정리해 보기로 했습니다. (이 글도 그다지 마음에 드는 건 아니네요. ㅠㅠ)
참고로 이 글은 ComfyUI 설치방법은 다루지 않습니다. 이 글 앞부분을 보면 설치방법이 있으며, ComfyUI 사용법도 상당부분 중복되는 내용이 있으니 참고하세요.
ComfyUI는 stable diffusion을 위한, 노드 기반의 GUI입니다. 이 글에서 다루는 내용은 아래와 같습니다.
- ComfyUI란?
- 텍스트-이미지 생성방법
- 이미지-이미지 생성방법
- 커스톰 노드(Custom node)
- AI 확대기(Upscaling) 확대기 사용방법
- ComfyUI 인페인트
- SDXL 워크플로
- LoRA 워크플로
ComfyUI란?
ComfyUI는 stable diffusion을 위한 노드 기반의 GUI입니다. ComfyUI에는 여러가지 박스(노드라고 함)를 사용하는데, 이 박스들을 잘 연결해서 이미지 생성 워크플로를 구성할 수 있습니다.
제가 소개시켜드린 AUTOMATIC1111 이나 EasyDiffusion도 웹UI로서 기본적으로는 형태만 다를 뿐 사용자의 입력을 받아 stable diffusion을 구동시켜주는 사용자인터페이스일 뿐입니다.
ComfyUI와 AUTOMATIC1111 비교
현재 가장 많이 사용되는 Stable dIffussion용 웹 GUI는 AUTOMATIC1111입니다. 이 블로그에 있는 스테이블 디퓨전 관련 글의 대부분도 AUTOMATIC1111을 기준으로 작성되었습니다. 그런데도 AUTOMATIC1111 대신 ComfyUI를 사용해야할 이유가 있을까요? 그 이유를 알아보겠습니다.
우선 ComfyUI를 사용할 때의 장점입니다.
- 경량: 속도가 빠르다.
- 유연: 자유롭게 설정할 수 있다.
- 투명: 데이터 흐름을 직접 볼 수 있다.
- 공유: 생성된 파일에 워크플로 전체가 들어 있어서 공유하기 쉽다.
- 프로토타이핑: 코딩대신 그래픽 인터페이스를 사용해 프로토타입을 제작할 수 있다.
하지만, ComfyUI에는 단점도 있습니다.
- 인터페이스의 일관성 부족: 워크플로별로 노드를 다르게 배치할 필요가 있으며, 직접 무엇을 변경시킬지 알아내어야 한다.
- 너무 세부사항이 많음: 일반적인 사용자라면 흐름이 어떻게 되는지 알 필요는 없다. 이미지가 잘 생성되면 그만이다.
결론적으로 그냥 이미지를 생성하기만 하거나, 스테이블 디퓨전에 대해 좀더 자세하게 알아보고 싶지 않다면 AUTOMATIC1111이 더 편리할 수 있습니다. 하지만, 제 경험으로는 동일한 작업을 할때 ComfyUI가 50% 정도 이상 빠르기 때문에 저는 ComfyUI를 주력으로 사용하고, AUTOMATIC1111을 보조로 사용할 계획입니다.
시작 방법
ComfyUI 사용법을 알기 위한 가장 좋은 방법은 샘플을 사용하는 것입니다. 따라서 이 글에서는 가장 간단한 text-to-image 워크플로그를 구성하면서 ComfyUI에 대해 알아보겠습니다. 이를 통해 가장 핵심적인 것을 이해하면, 어떻게 하면 직접 튜닝할 수 있을 지도 파악하실 수 있을 것입니다.
기본적인 제어방법
ComfyUI에선 마우스만으로 거의 모든 제어가 가능합니다. 마우스휠 (또는 두손가락 벌리기)을 사용해서 확대 또는 축소가 가능합니다. 빈 캔버스를 마우스로 클릭하고 드래그하면 캔버스를 이동시킬 수 있습니다.
또 가장 중요한 것중의 하나가 노드와 노드사이를 링크로 연결해야 하는데, 이때는 마우스를 드래그&드롭하면 됩니다. 물론 서로 호환되는 경우에만 연결이 되고 아니면 그냥 취소 됩니다.
마지막으로 Cont-Enter 를 치면 현재 설정이 대기열(Queue)로 들어가게 되는 것도 기억하면 좋습니다.
텍스트-이미지(Txt2Img) 작업 방법
먼저 ComfyUI를 사용해서, 텍스트 프롬프트를 입력해 이미지를 생성하는 방법을 알아보겠습니다. 이 예제를 통해 ComfyUI의 작동법을 알 수 있으며, 부수적으로 Stable Diffusion이 어떻게 작동되는지 좀더 자세하게 이해할 수 있습니다.
맨 처음으로 이미지 생성해보기
ComfyUI를 처음으로 실행시키면 아래와 같은 화면이 나타날 것입니다. 이 화면이 아닐 경우, [Load Default] 버튼을 누르면 이 화면으로 초기화 됩니다.

이 기본 화면에는 여러개의 사각박스(노드)와, 이들 박스를 서로 연결하는 링크로 구성됩니다.
노드는 각각 특별한 기능을 하는데, 여기에서는 체크포인트 모델을 선택하는 Load Checkpoint 노드, 프롬프트를 입력하면 토큰(token)으로 변환해주는 Clip Text Encoder 노드 등을 볼 수 있습니다. 각각의 노드는 실제로는 어떤 프로그램을 실행시키는 역할을 합니다. 프로그램을 짜본 분이시라면, 이들 노드를 함수라고 생각해도 됩니다.
이들 노드는 세 부분으로 구성됩니다.
- 입력 슬롯: 노드 왼쪽에 있는 점으로, 여기에 링크가 연결됩니다.
- 출력 슬롯: 노드 오른쪽에서 링크가 연결되는 점입니다.
- 파라미터: 블록 아래쪽에 있는 여러가지 필드들입니다.
링크는 각각의 노드의 출력 슬롯과 입력슬롯을 연결해주는 선입니다.
일단 이 정도로 하고 이미지를 생성해 보겠습니다.
1. 모델 선택
제일 먼저 할 일은 [Load Checkpoint] 노드에서 Stable Diffusion 체크포인트 모델을 선택하는 것입니다. 이 노드 아래쪽에 있는 모델 이름을 클릭하여 사용할 체크포인트 파일을 선택합니다.

노드가 너무 작아서 안보이면 마우스 휠(또는 두손가락 벌리기)로 화면을 확대 축소시킬 수 있으며, 노드 오른쪽 아래 귀퉁이를 끌면 노드의 크기를 변경시킬 수 있습니다. 참고로, 모델이 없어서 선택할 수 없는 경우 모델을 직접 다운로드 받거나 기존 AUTOMATIC1111 에 설치한 모델을 사용할 수도 있습니다. 자세한 내용은 이 글 첫부분을 읽어보시기 바랍니다.
2. 프롬프트 입력
프롬프트는 [CLIP Text Encode] 노드를 통해 입력합니다. 기본화면에서는 아래와 같이 [CLIP Text Encode] 노드가 2개 있는데, 위쪽이 긍정적 프롬프트, 아래쪽은 부정적 프롬프트를 입력하는 곳입니다.
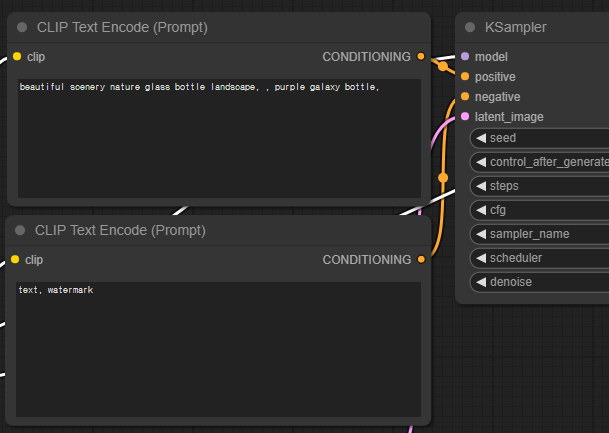
[CLIP Text Encode] 노드는 기본적으로 입력된 프롬프트를 토큰으로 변환한 후, 이를 임베딩(embeddings)으로 인코딩하는 역할을 합니다.
프롬프트를 입력할 때에는 AUTOMATIC1111과 마찬가지로 (keyword:weight)와 같은 방식으로 원하는 키워드의 가중치를 변경할 수 있습니다. 예를 들어 (night:1.2)는 night이라는 키워드를 강조하고, (night:0.8)은 키워드 효과를 줄이게 됩니다.
사실 이 두 노드는 동일한 노드입니다. 기능적으로는 전혀 차이가 없죠. 다만, 우측에 있는 CONDITIONING 출력 슬롯이 연결되는 곳만 다릅니다. 위의 노드는 KSamper 노드의 positive에 연결되고, 아래 노드는 negative에 연결되죠. 이 때문에 위는 긍정적 프롬프트의 역할을 하고 아래는 부정적 프롬프트의 역할을 하게 됩니다. 이 링크를 서로 반대로 연결하면 노드의 역할이 바뀌게 됩니다.
3. 이미지 생성
이제 오른쪽에 있는 메뉴에서 [Queue Prompt] 누르고(Cont-Enter 를 눌러도 됩니다) 잠시 기다리면 최초의 이미지가 생성됩니다. 아래처럼요. 간단합니다^^
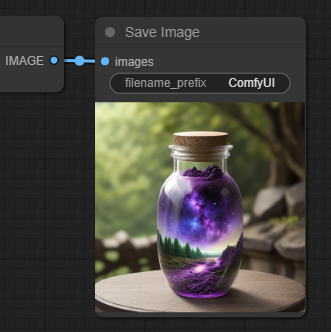
실행 과정 설명
Queue Prompt를 누르면 맨 처음 [Load Checkpoint]로부터 시작해서 여러개의 노드가 초록색 선으로 강조되었다가 다음으로 넘어가는 것을 보실 수 있습니다. 이렇게 강조되는 순간이 해당 노드가 실행되는 것입니다. 이처럼 ComfyUI를 사용하면 stable diffusion이 어떻게 작동되는지 이해하기 쉽고, 이를 통해 세세하게 조정할 수 있다는 장점이 있습니다.
이를 위해 각각의 노드에 대해 자세히 알아보겠습니다. 스테이블 디퓨전에 관한 이론에 관심이 없다면 그냥 넘어가셔도 됩니다.
[Load Checkpoint] 노드
[Load Checkpoint] 노드는 말그대로 체크포인트 모델을 선택하고 불러올 때 사용합니다. 이 노드 오른쪽에 세가지 출력 슬롯이 있는데, 이것은 바로 체크포인트 모델의 구성요소와 동일합니다. 우리는 일반적으로 체크포인트 파일이라고 하지만, 실제로는 아래의 세가지가 포함되어 있는 겁니다.
- MODEL : 잠재(latent) 공간에서의 잡음 예측(noise predictor) 모델
- CLIP : 프롬프트를 처리하는 데 사용되는 언어 모델
- VAE : 잠재 공간과 이미지 공간의 변환을 담당하는 VAE(가변 자동 인코더: Variational AutoEncoder)
출력 슬롯 Model은 샘플러 노드로 연결됩니다. 샘플러 노드는 이 Model을 사용해서 역 확산(reverse diffusion)을 수행하죠.
출력 슬롯 CLIP은 텍스트 인코드 노드로 연결되어, 프롬프트를 해석하고 임베딩으로 변환하는 역할을 수행합니다.
마지막으로 VAE는 맨 마지막에 위치한 VAE Decode 노드로 연결되며, 이 노드에서는 잠재 이미지를 실제 이미지로 변환할 때 사용합니다.
[CLIP Text Encode] 노드

[CLIP Text Encode] 프롬프트를 입력받고, 이를 CLIP 언어모델에 공급합니다. CLIP 이란 OpenAI에서 개발한 언어 모델로, 프롬프트에 포함된 단어들을 임베딩(embeddings)으로 변환하게 됩니다.
[Emptry latent image] 노드

text-to-image 프로세스는 잠재 공간(latent space)에서 랜덤(무작위) 이미지를 처리하여 이미지를 생성합니다. [Embty Latent Image] 노드는 바로 이 랜덤 이미지를 생성해서 샘플러 노드에 전달하는 기능을 합니다.
여기에서 지정한 width와 height는 실제 이미지의 크기와 동등하므로, 최종 이미지의 크기를 여기에서 결정할 수 있습니다(확대기(Upscaler)를 사용할 경우 달라짐). 따라서 이 노드에서 width와 height를 변경하면 생성되는 이미지의 크기를 설정할 수 있습니다.
또한 batch_size는 한번에 생성하는 이미지의 수를 결정합니다.
[KSampler] 노드

KSampler는 스테이블 디퓨전을 통한 이미지 생성에서 가장 핵심이라고 할 수 있습니다. 샘플러는 무작위 랜덤 이미지로부터 텍스트 프롬프트에 맞도록 노이즈를 순차적으로 제거하면서 이미지를 생성하는 기능을 합니다. 그 중에서 KSampler란 이 저장소에서 구현한 샘플러를 말합니다.
[KSampler]에 포함된 파라미터는 아래와 같습니다.
- 씨드(Seed): 잠재 이미지의 초기 잡음을 제어하는 무작위 씨드 값입니다. 즉, 이 번호를 사용하여 초기 랜덤 이미지를 구성합니다.
- control_after_generate: 이미지를 생성한 후, 씨드 값을 어떻게 할지를 결정합니다. 무작위로 바뀌게 할 수도 있고(randomize), 1씩 증가(increment) 또는 감소(decrement)하게 할 수도 있으며, 같은 값(fixed)으로 고정되게 설정할 수도 있습니다.
- 단계수(steps) : 샘플링 단계의 수 : 높은 값을 입력할 수록 결함이 줄어듭니다.
- 샘플러 이름(sampler name): 다양한 샘플러 알고리즘 중 하나를 선택합니다.
- 스케줄러(Scheduler): 각 단계별로 노이즈를 얼마나 제거할지를 결정합니다. 매 단계별로 일정한 분량 만큼 제거하는 알고리즘도 있고, 처음엔 많이 제거하고 뒤로 갈수록 제거하는 양이 줄어드는 알고리즘도 있습니다.
- Denoise(잡음 제거량): 최초의 잡음을 얼마나 제거할지를 결정합니다. 1은 전체를 제거한다는 뜻입니다.
참고로 이 워크플로는 가장 기본적인 txt2img 만 가능합니다. 또한 SDXL 의 경우 base 모델과 refiner 모델로 구성되는데, KSamper에서는 이것을 사용할 수 없습니다. SDXL 을 적용하는 방법은 이 글을 읽어보시기 바랍니다.
이미지-이미지(Image to Image) 작업 방법
ComfyUI 예제 사이트에 들어가시면 다양한 워크플로 예제가 있습니다. 이중 img2img 워크플로 예제에는 아래와 같은 그림이 포함되어 있습니다. 이 그림을 다운로드 받아서 캔버스에 드래그&드롭 하거나, [Load] 버튼을 누르고 이 그림을 선택하면, img2img 워크플로를 그대로 사용할 수 있습니다. (물론 아래 그림을 다운로드 받아 사용하셔도 됩니다)
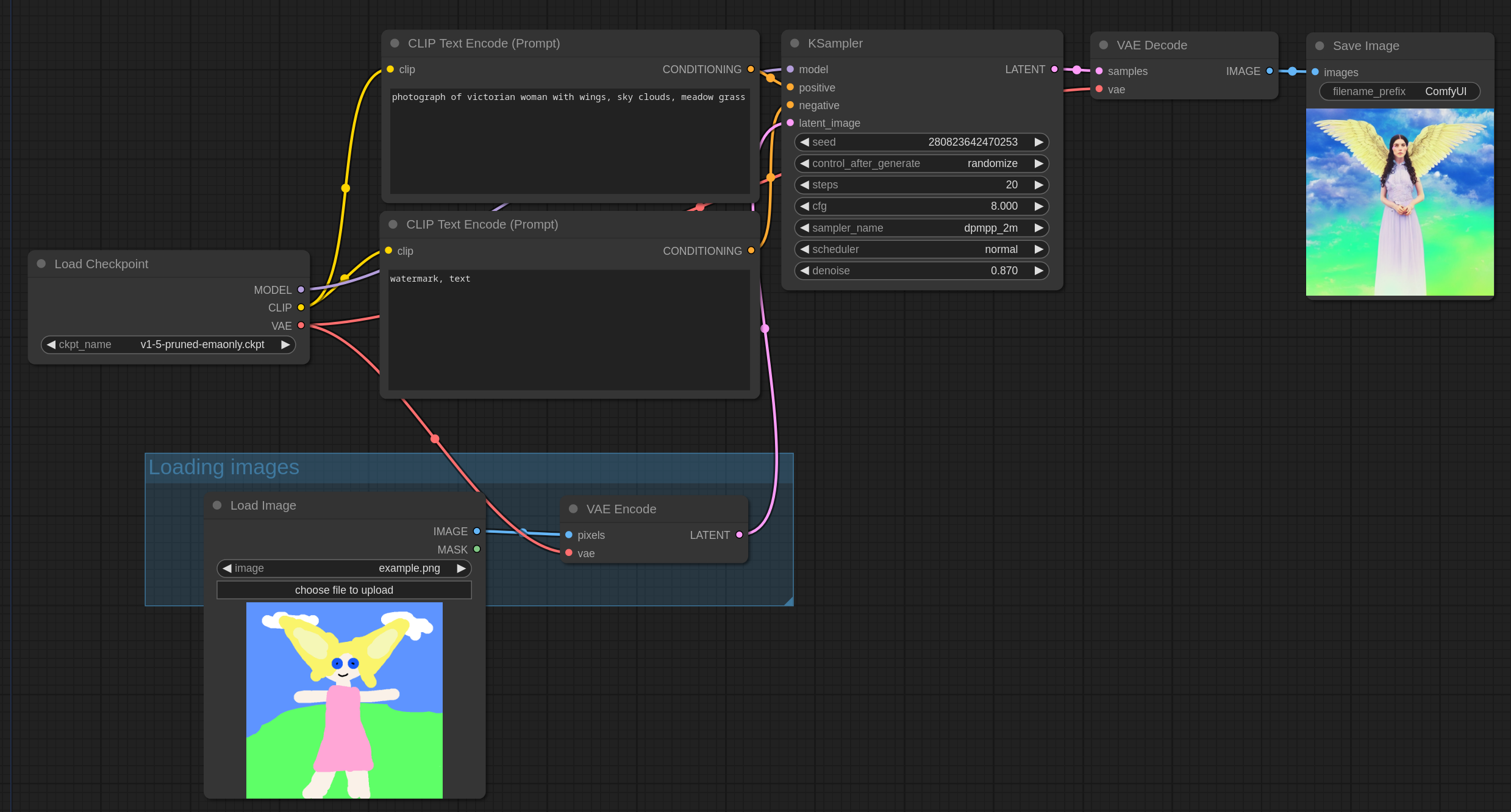
Img2img 워크플로가 txt2img 워크플로와 다른 점은 [Empty Latent Image] 노드로 무작위 이미지를 사용하는 대신 [Load Images] 노드를 사용하여 바탕이 되는 이미지를 직접 제공한다는 것입니다.
[Load Images] 노드

[Load Images]노드는 간단합니다. 아래쪽에 [Choose file to upload]를 누르면 원하는 이미지를 직접 선택할 수 있고, 위쪽에 있는 example.png를 누르면 ComfyUI_windows_portable\ComfyUI\input 폴더에 있는 이미지를 사용할 수 있습니다.
출력슬롯 IMAGE 는 이렇게 선택된 이미지를 그대로 내보내게 됩니다. 그런데 이 이미지는 이미지 공간상의 이미지이기 때문에 Stable Diffusion에서 직접 사용할 수는 없고 변환이 필요합니다. 아래 [VAE Encode] 노드가 이 역할을 해줍니다.
[VAE Encode] 노드

VAE Encode 노드는 입력받은 이미지를 체크포인트 파일에 포함된 vae 모델을 사용하여 잠재 이미지로 변환해 주는 역할을 합니다. 다르게 손볼 것은 없지만, 반드시 이 노드를 거쳐야만 일반 이미지를 사용할 수 있음을 기억해야 합니다.
참고로 여기에서는 VAE Encode 노드가 사용되었지만, 이미지 출력에는 VAE Decode 노드가 사용됩니다. 서로 반대되는 역할을 해주는 것입니다.
img2img 사용법
사용방법은 간단합니다. txt2img 워크플로 사용하는 방법과 거의 동일하기 때문입니다.
- [Load Checkpoint] 노드에서 원하는 체크포인트 모델을 선택합니다.
- [CLIP Text Encode] 노드에서 프롬프트와 부정적 프롬프트를 적당하게 입력합니다.
- 필요시 [KSampler] 노드에서 denoise (잡음제거강도, denoising strenth)를 조정합니다. 이 값을 크게 할 수록 원본 이미지와 달라지게 됩니다.
- 마지막으로 Queue Prompt 버튼을 눌러주면 이미지가 생성됩니다.
AUTOMATIC1111 초보자 가이드의 img2img 에서 사용한 이미지를 사용해 적용해 보겠습니다. 여기에서 입력으로 사용한 이미지는 이 링크를 다운로드 받으면 됩니다. 설정은 아래와 같습니다.
모델: DreamShaper
프롬프트: A photorealistic illustration of a dragon
Denois: 0.6

위의 그림에는 모든 워크플로가 포함되어 있으므로 받아서 사용하실 수 있습니다.
 |
 |
한가지 말씀드릴 것은 위의 img2img 워크플로는 입력된 이미지가 그대로 잠재 이미지가 되기 때문에 출력된 이미지의 크기를 조정할 수 없는 한계가 있습니다. 이를 보완하기 위해서는 [Load Images] 노드와 [VAE Encode] 노드 사이에 [Upscale]노드를 추가해야 합니다만, 여기에서는 더 이상의 설명을 생략합니다.
커스톰 노드(Custom Node)
ComfyUI를 사용하다보면, 기본 노드만으로는 많이 부족하다는 것을 알게됩니다. 기본 노드는 진짜 꼭 필요한 기능만 있기 때문에 조금 편하게 사용하려다 보면 새로운 기능이 들어간 노드가 필요할 수 있습니다. 이럴 때 필요한 것이 커스톰 노드(Custom node)입니다.
ComfyUI에서는 커스톰 노드를 개발하기 쉽기 때문에 정말 다양한 커스톰 노드가 존재합니다. 그런데 아무 커스톰 노드나 사용하다보면 다른 사람과 워크플로를 공유하기 힘들어질 수도 있기 때문에 가능한 한 널리 사용되는 커스톰 노드를 사용하는 것이 좋습니다.
ComfyUI Manager
ComfyUI Manager는 다른 커스톰 노드 혹은 모델들을 설치하고 관리해주는 커스텀 노드입니다. 수많은 커스톰 노드를 쉽게 관리할 수 있어 거의 필수적이라고 할 수 있습니다.
ComfyUI Manager 설치방법
윈도 11의 명령 프롬프트(cmd) 또는 파워쉘(PowerShell)을 열고 아래의 커스톰 노드 폴더로 들어갑니다.
cd ComfyUI_windows_portable\ComfyUI\custom_nodes그 다음 아래의 명령을 실행시킵니다.
git clone https://github.com/ltdrdata/ComfyUI-Manager그 다음 ComfyUI를 새로 시작되면 ComfyUI Manager 가 적용됩니다.
ComfyUI Manager 사용방법
설치가 완료되면 아래 그림과 같이 명령 메뉴 아래에 [Manage] 버튼이 추가됩니다.

이 버튼을 누르면 다음과 같은 ComfyUI Manager Menu가 나타납니다.

여기에 있는 메뉴의 내용은 아래와 같습니다.
- [Install Custom Nodes] 커스톰 노드를 설치/제거할 수 있습니다.
- [Install Missing Custom Nodes] 현재 워크플로에 있지만, 빠진 노드를 설치해줍니다. 특히 다른 사람이 생성한 워크플로를 가져와서 사용할 경우, 그 사람이 사용했던 커스톰 노드중에서 자신에게 없는 노드를 자동으로 설치해 줘서 매우 유용합니다.
- [Install Model] 체크포인트 모델, AI 확대기 모델, VAE, LoRA, ControlNet 모델 등을 설치합니다.
- [Update ComfyUI] ComfyUI를 업데이트합니다.
- [Fetch Updates] 커스톰 노드의 업데이트를 확인합니다. 재시작해야 적용됩니다.
- [Alternatives of A1111] 잘 모르겠는데, AUTOMATIC1111 확장중에서 ComfyUI에서 사용가능한 것을 검색하고 설치할 수 있는 것 같습니다.
- [ComfyUI Community Manual] 매뉴얼을 볼 수 있는데 많이 허덥합니다.
[Install Custom Nodes] 메뉴를 누르면 아래와 같은 화면이 나타납니다. 여기에서 사용가능한 커스톰 노드를 찾아보고 설치/제거할 수 있습니다.

AI 확대기(Upscaling) 확대기 사용방법
스테이블 디퓨전에서 AI 확대기를 사용하는 방법은 아주 다양합니다. 여기에서는 그중 몇가지만 소개시켜드립니다.
AI upscale
AI upscaler는 이미지를 확대하면서 상세한 부분을 채워주는 AI 모델입니다. 이 모델은 Stable diffusion 모델은 아니고, 원래 이미지를 확대하기 위한 목적으로 학습시킨 신경망(neural network)입니다. 아래는 ComfyUI upscale 예제에서 가져온 워크플로입니다. 당연히 아래 그림도 ComfyUI 캔버스에 Drag&Drop하면 이 워크플로가 똑같이 설정됩니다.

이 워크플로를 불러와보면 아시겠지만, 다른 부분은 아래부분 뿐입니다. 즉 [VAE Decode]에서 바로 [Save Image] 노드로 넘어가지 않고 [Upscale Image (using Model)] 이 사이에 끼어 있다는 것입니다.

[Upscale Image (using Model)] 노드
AI 확대기 모델을 이용해서 이미지를 확대하는 기능을 하는 노드입니다. 아래와 같이 마우스 우클릭 후, Add node -> image -> upscaling -> Upscale Image (using Model)을 사용하여 추가할 수 있습니다.

[Load Upscale Model] 노드
Add node -> loaders -> Load Upscale Model 을 통해 불러들일 수 있습니다. Upscale 모델은 models/upscale_models 폴더에 넣어주시면 됩니다. AUTOMATIC1111에 이미 모델을 다운로드 받은 상태라면 함께 사용할 수 있습니다. (방법은 이 글 을 참고하세요.)
AI 확대기 모델은 Upscaler Wiki에서 찾아보실 수 있습니다. 너무 많아서 찾기 귀찮으시면 그냥 ComfyUI Manager에 들어가서 [Install Models] 버튼을 누른 후, upscale 유형의 모델을 다운로드 받아서 사용하시면 됩니다.
이렇게 설정한 상태에서 [Queue Prompt] 버튼을 누르면 작업이 수행됩니다.
ComfyUI에 대해 좀 더 잘 이해하고 싶으시다면 위쪽에 있는 txt2img 또는 img2img 워크플로에 upscale 워크플로를 추가해보면 좋습니다. 직접 테스트해보시길~
Hi-res fix
Hi-res fix 를 사용하는 예제는 ComfyUI 2 Pass txt2img(Hires fix) 에 있습니다. 아래는 여기에 포함된 이미지로서 이 그림을 ComfyUI 캔버스에 Drag&drop하면 Hires-fix 워크플로를 사용할 수 있습니다.

이 예제는 지금까지 사용한 워크플로보다 상당히 복잡해 보이지만, 이를 이해하면 ComfyUI의 장점을 이해할 수 있습니다. 자세히 살펴보죠.
먼저 좌측 부분은 맨 위에 있는 txt2img와 완전히 동일합니다. 즉, 프롬프트와 부정적 프롬프트를 조건부여로 사용하고, 샘플러를 통해 잡음 제거를 수행합니다. 다른점은 자주색으로 표시된, 여러가지 노드를 그루핑해주는 Group 이 추가된 것 뿐입니다. (Group 은 캔버스 우클릭후 Add Group을 선택하면 됩니다)

우측에는 아래와 같은 Hi-res Fix 그룹이 있습니다. 그런데... Upscale Latent라는 노드가 추가되어 있고 또다른 KSampler 노드가 추가되어 있다는 점만 다릅니다.
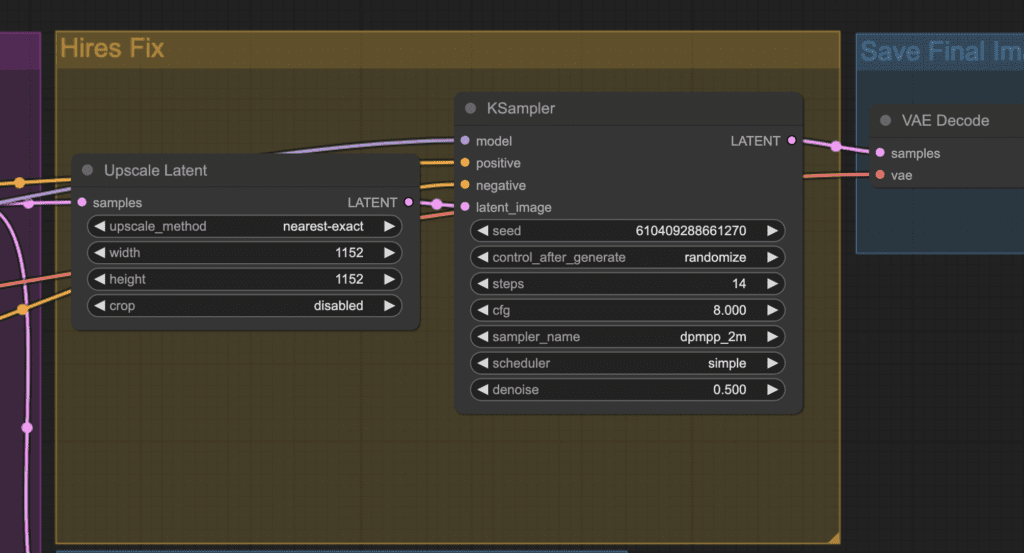
[Upscale Latent] 노드
이 노드는 이미지를 확대시켜주는 노드입니다. 위의 경우엔 512x512 크기의 원래 이미지를 1152 x 1152 로 확대시켜줍니다. 다만 이름에서 알 수 있는 것처럼 이미지 공간의 이미지가 아니라, 잠재(latent)공간의 이미지를 확대시켜줍니다.
이 노드는 아래와 같이 Add node -> latent -> Upscale Latent 를 선택하면 추가할 수 있습니다.
결국 Hires-fix 란, txt2img 워크플로를 통해 잠재 이미지를 생성한 후, 이 잠재 이미지를 확대 한 후 다시한번 샘플링을 돌려주는 구조로 되어 있음을 알 수 있습니다. 대신 이 두번의 샘플링의 단계수(step)은 작은 걸 확인할 수 있습니다. 즉, 첫번째 단계에서는 12단계, 두번째 단계에서는 14단계, 총 26단계의 샘플링을 수행합니다. (txt2img는 20번을 수행하네요. 물론 수정할 수 있지만요)
SD Ultimate upscale - ComfyUI 버전
SD Ultimate upscale은 AUTOMATIC1111에서 널리 사용되는 확대기 확장입니다. 이것을 ComfyUI에서도 사용할 수 있습니다.
설치방법
ComfyUI Manger 를 실행시키고 [Install Custom nodes]를 누릅니다. 그리고 UltimateSDUpscale을 찾아 맨 오른쪽에 있는 [Install] 버튼을 누르면 추가할 수 있습니다. 오른쪽 위에 있는 검색창을 사용해도 되고요.
ComfyUI를 다시 실행시켜야 적용됩니다.

워크플로 작성하기
SD Ultimate Upscaler는 커스톰 노드이기 때문에 ComfyUI 예제사이트에는 등록되어 있지 않습니다. 그래서 직접 생성해 보겠습니다. 출발점은 AI Upscale 에 있는 워크플로입니다.
여기에 조금 전 추가한 커스톰 노드를 추가합니다. Add Node -> Image -> upscaling -> Ultimate SD Upscale을 선택해 주면 됩니다.
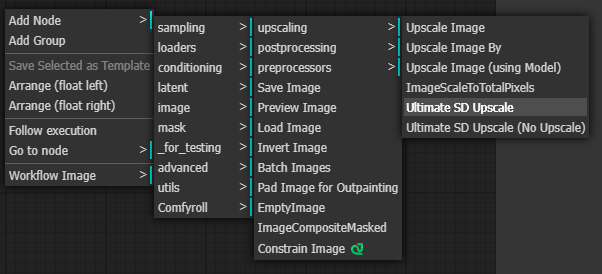
Ultimate SD Upsclae노드는 아래와 같습니다. 엄청 사이즈가 크네요.

여기에서 왼쪽 입력슬롯은 아래와 같이 연결합니다.
- image - [VAE Decode] 노드의 IMAGE 슬롯
- model - [Load Checkpoint] 노드의 MODEL 슬롯
- positive - 긍정적 프롬프트에 해당하는 [CLIP Text Encode] 노드의 CONDITIONING 노드
- negative - 부정적 프롬프트에 해당하는 [CLIP Text Encode] 노드의 CONDITIONING 노드
- vae - [Load Checkpoint] 노드의 VAE 슬롯
- upscale_model - [Load Upscale Model] 의 UPSCALE_MODEL
출력 슬롯은 아래와 같이 연결합니다.
- IMAGE - [Save Image] 노드의 image 슬롯
기타 위에서 tile_width와 tile_height를 1024로 바꿔주고 Queue Prompt를 입력하면 이미지가 생성됩니다. 원하시면 아래의 이미지를 캔버스에 떨어뜨리면 동일한 워크플로를 사용할 수 있습니다.

ComfyUI 인페인트
인페인트는 이미지의 일부분을 재생성해서 고치는 기능입니다. 옷색깔을 바꾸고 싶다거나, 얼굴을 다른 사람으로 대체하는 등 적용방법은 무궁무진합니다. 자세한 내용은 AUTOMATIC1111 인페인트 기초를 읽어보시기 바랍니다.
저는 AUTOMATIC1111 인페인트 기초에서 사용한 이미지를 사용합니다.

1. 인페인트 워크플로 불러오기
ComfyUI inpainting 예제에서 워크플로를 불러옵니다. 아래 그림을 저장한 후, 캔버스에 드래그&드롭해도 됩니다.

이 워크플로는 기본적으로 img2img 워크플로와 거의 비슷합니다. 다만, [VAE Encode] 노드 대신 [VAE Encode (for inpainting)] 노드를 사용했다는 것만 다릅니다.
2. 이미지 업로드
여기에서 아래와 같이 [choose file to upload] 버튼을 눌러 저장한 파일을 불러들입니다.

3. 마스크 생성
그림을 우클릭한 후, [Open in MaskEditor] 를 누릅니다.

그러면 다음과 같은 창이 뜨는데, 왼쪽 아래 Thickness를 적당히 조정해서 새로 그리고 싶은 부분을 칠한 후, 우측아래 [Save to node]를 누르면 마스크가 저장됩니다.
4. 파라미터 조정
다음과 같이 설정합니다. 이미지 크기는 원본 이미지의 크기와 동일합니다.
모델: DreamShaper
프롬프트: [emma watson: amber heard: 0.5], (long hair:0.5), headLeaf, wearing stola, vast roman palace, large window, medieval renaissance palace, ((large room)), 4k, arstation, intricate, elegant, highly detailed
부정적 프롬프트: ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, bad anatomy, watermark, signature, cut off, low contrast, underexposed, overexposed, bad art, beginner, amateur, distorted face, b&w
CFG: 7
Sampling Steps:25
5. 인페인트 실행
마지막으로 [Queue Prompt] 버튼을 누르면 실행됩니다.
그런데... DreamShaper 모델을 사용하니 완전히 맥락없는 이미지가 생성되네요. 꿈에 나올까 무섭다....

그런데 원래의 워크플로를 불러들이면 512-inpainting-ema 라는 모델을 사용하고 있습니다. 그래서 이 모델을 다운로드 받아 새로 시작해 봤더니 좀 낫네요.

AUTOMATIC1111 을 사용할 때는 inpaint 전용모델을 사용한 적이 없었는데, comfyUI에서는 왜 꼭 이 모델을 사용해야 하는지 모르겠는데 아무튼 그다지 좋다는 생각은 안드네요. 만약 완전히 다른 분위기를 내고 싶어서 lora 를 사용한다면 제대로 될지도 잘 모르겠구요. 일단 제가 확실히 파익할 때까지는 인페인트는 AUTOMATIC1111을 사용하는 게 낫겠다 싶습니다.
SDXL 워크플로
ComfyUI 는 세세한 조정이 가능하기 때문에 Stable Diffusion XL (SDXL)을 가장 빨리 지원한 GUI입니다. 아래는 ComfyUI 예제 사이트에 올려져 있는 SDXL 워크플로를 배치만 약간 바꾼 것입니다. 아래 워크플로를 다운로드 받은 후 ComfyUI 캔버스에 떨어뜨리면 사용할 수 있습니다.
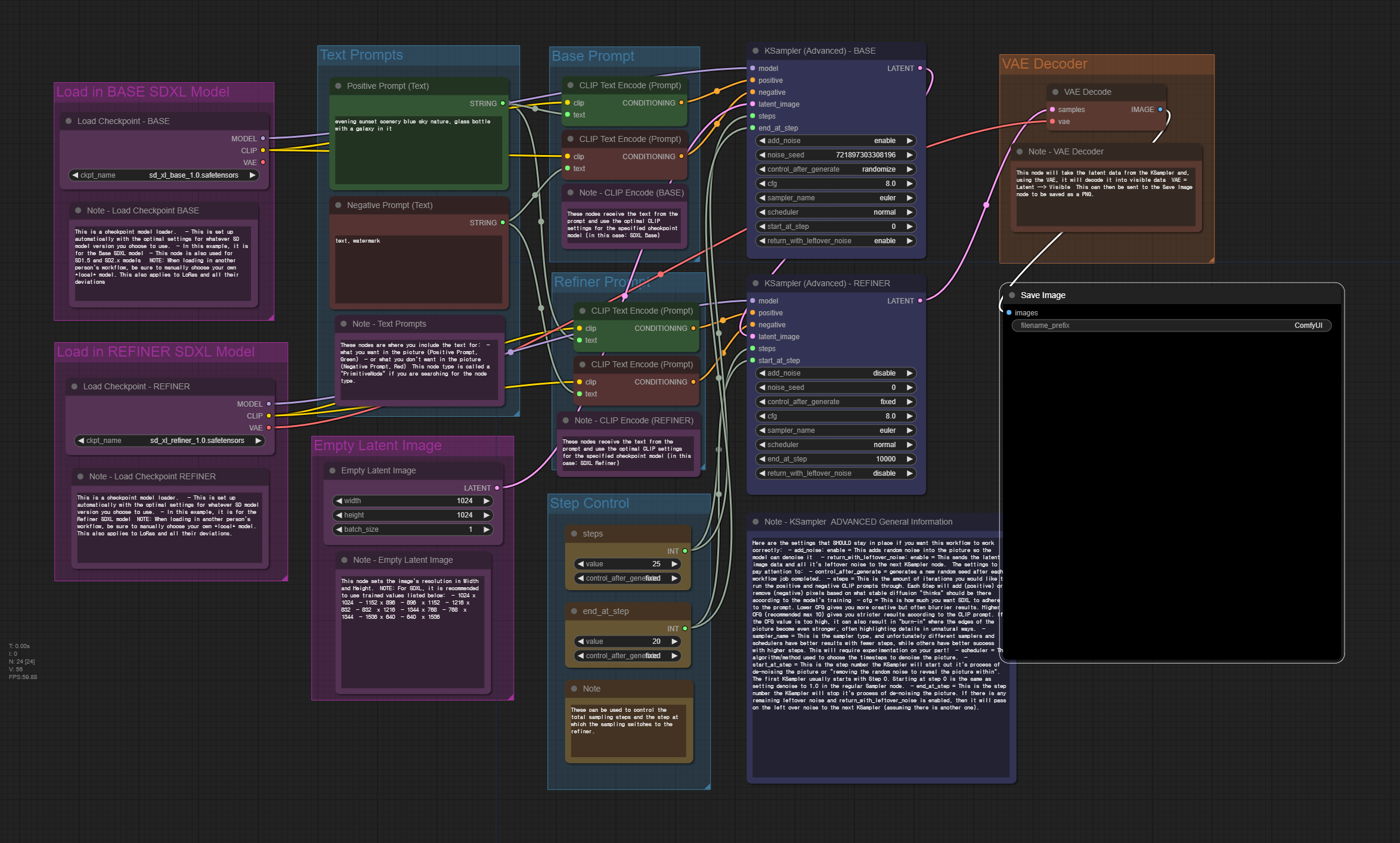
이 워크플로에는 각각의 노드에 대한 설명이 포함되어 있어서 복잡해 보입니다만, 실제로는 그다지 복잡한 것 없고, 그냥 프롬프트와 부정적 프롬프트, 그리고 이미지 크기만 정한후 [Queue Prompt] 버튼만 누르면 이미지가 생성되도록 설정되어 있습니다.
SDXL 워크플로에 대해 좀더 자세히 알고 싶으시면 아래 글들을 읽어보시면 도움이 되실겁니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(1) - 기초 - 아주 간단한 기본 SDXL 워크플로를 생성합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(2) - 조건부여 - SDXL 에만 적용되는 조건부터를 추가하고, 조건부여 파라미터 변경에 따른 이미지 영향을 시험합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(3) - Refiner - 완전한 SDXL 프로세스를 위해 refiner 모델을 추가합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(4) - LoRA - 커스텀 노드를 설치하고 LoRA를 사용하는 워크플로를 생성합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(5) - img2img - 이 글. img2img 를 사용하는 워크플로를 생성합니다.
LoRA 워크플러
LoRA는 체크포인트 모델을 변경해주는 크기가 작은 모델로서, 어떤 인물이나 스타일을 바꾸는데 요긴하게 사용됩니다. 자세한 내용은 이 글을 읽어보시기 바랍니다.
ComfyUI에서는 ComfyUI 예제사이트에 올려진 아래 파일을 다운로드 받고 ComfyUI 캔버스에 Drag&Drop하면 LoRA를 사용하는 방법을 아실 수 있습니다.
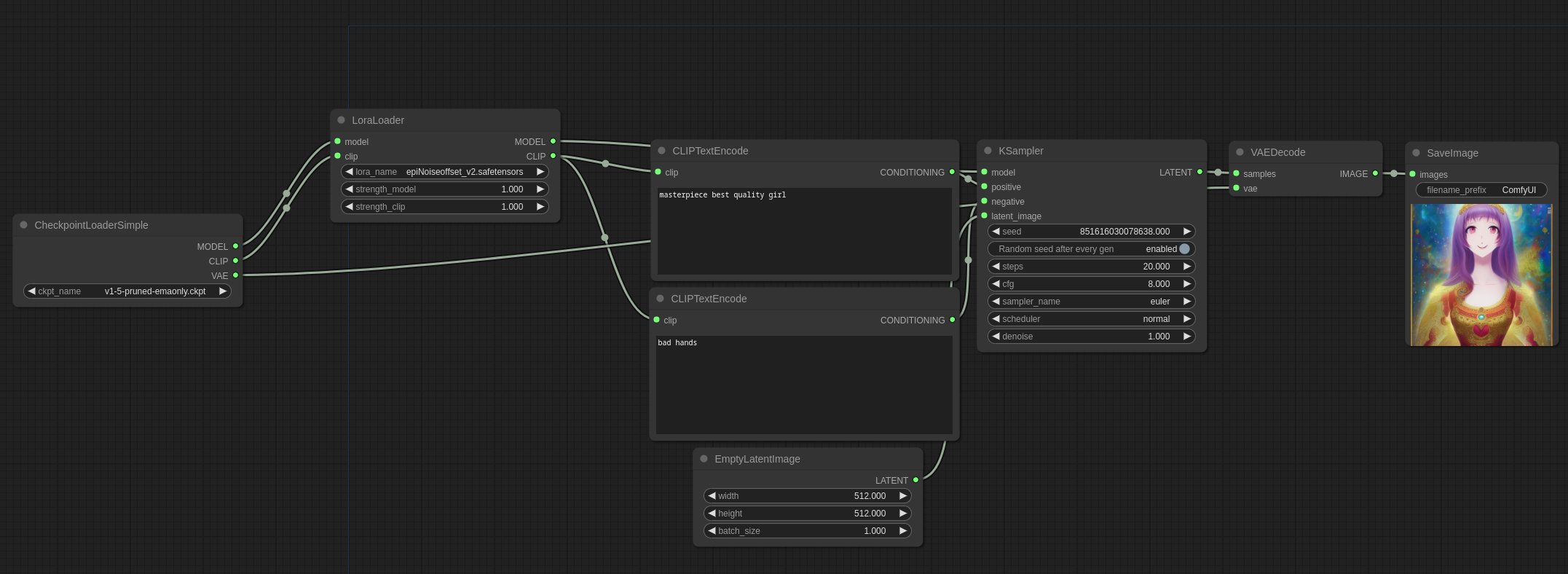
이 워크플로도 맨 위에 있는 txt2img 워크플로와 거의 비슷합니다. 다만, 아래 그림과 같이 [Load Checkpoint] 노드와 [CLIP Text Encode] 노드 사이에 [Load LoRA] 노드가 끼어 있는 것만 다릅니다.

특히 주목할 점은 Checkpoint 모델의 Model과 CLIP을 받아서 또다른 Model과 CLIP으로 바꿔 내보낸다는 점입니다. 즉, LoRA 는 체크포인트 모델의 일부만 변경시키는 역할을 한다는 것을 아실 수 있을 겁니다.
사용하는 방법은 일반적인 ComfyUI 워크플로와 비슷합니다.
- 체크포인트 모델 선택
- LoRA 모델 선택
- 프롬프트와 부정적 프롬프트 입력
- [Queue Prompt] 버튼 선택
아래는 LoRA 모델 사용법에 있는 예제를 그대로 따라 해 본 것입니다. 아래 그림을 Drag&Drop하면 그대로 복원해볼 수 있습니다.

다중 LoRA 사용법
여러가지 LoRA를 한꺼번에 적용하는 방법도 기본적으로는 동일합니다. [Load LoRA] 노드를 여러개 끼워넣기만 하면 되기 때문입니다. 아래는 ComfyUI 예제사이트에 올려진 LoRA 모델을 두개 적용하는 워크플로로서, 그냥 쉽게 이해하실 수 있을 겁니다.
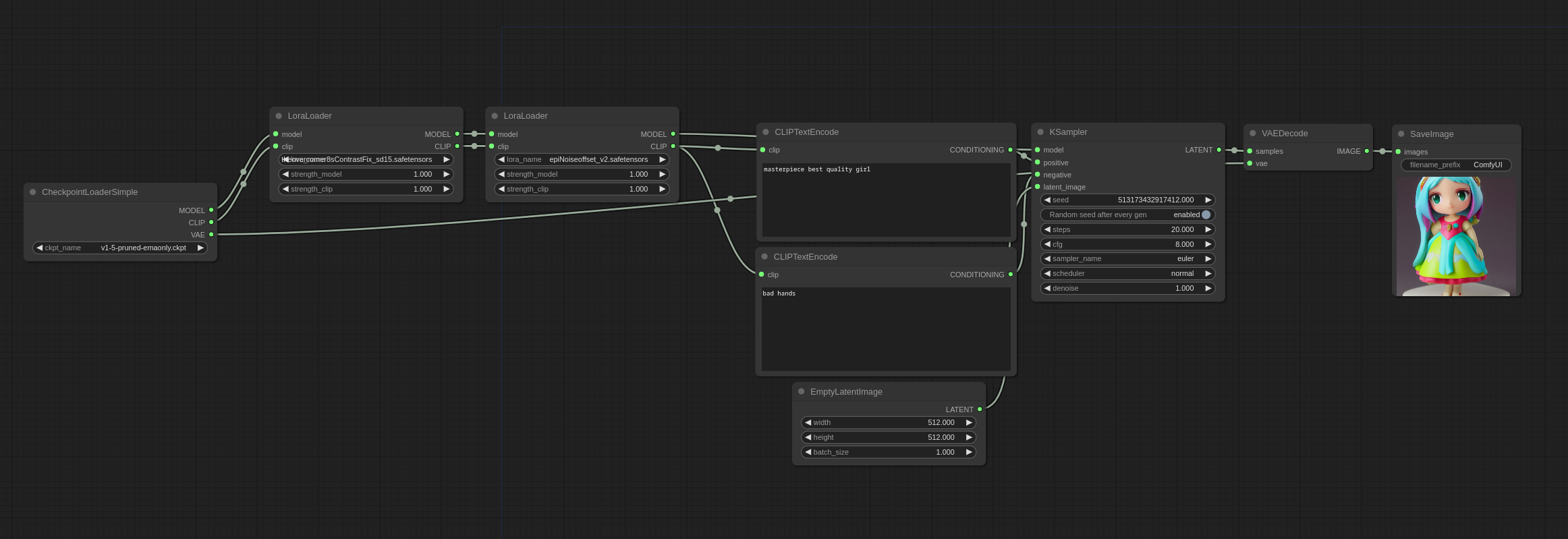
이상입니다. 원본 글에는 몇가지 내용이 더 있었지만, 이정도로 충분할 것 같네요. 물론 이것만으로는 ComfyUI를 자유자재로 쓰기는 힘들지만, 대충 원리는 충분히 설명드린 것 같습니다.
민, 푸른하늘
====
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 투토리얼
- ComfyUI를 위한 유용한 정보
- ComfyUI와 SDXL 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기