
각각 촬영된 두 사람을 사진 한장에 합치고 싶으십니까? 예를 들면 예쁜 여배우님과 자신이 악수하고 있는 사진을 만들어보면 어떨까요? 이 글에서는 FLUX.1 Kontext [dev] 모델을 사용하여 이미지를 합치고 편집하는 워크플로를 설명합니다.
소프트웨어
이 글에서는 스테이블 디퓨전용 GUI중에서도 제일 강력하며, 현재 거의 대세로 자리잡고 있는 ComfyUI를 사용합니다. ComfyUI가 처음이시라면, 설치 및 기본 사용방법 및 초보가이드를 확인하시기 바랍니다.
Flux.1 Kontext 소개
FLUX.1 Kontext 모델은 이미지 생성과 편집 기능을 하나로 통합한 모델입니다. 즉, 그냥 텍스트-이미지 방식으로 이미지를 생성할 수 있을 뿐 아니라, 참조 이미지를 사용하여 새로운 이미지를 생성할 수도 있고, 생성된 이미지를 간단한 명령으로 편집할 수도 있습니다. 자세한 내용은 여기를 읽어보시기 바랍니다.
따라하기
1 단계: 모델 다운로드
이 워크플로에서는 flux1-kontext-dev.safetensors모델을 사용합니다. 이 파일을 다운로드 받은 후, ComfyUI\models\diffusion_models 폴더에 넣어줍니다.
텍스트 인코더 모델 clip_l.safetensors 및 t5xxl_fp16.safetensors을 다운로드 받은 후, ComfyUI\models\clip 폴더에 넣어줍니다.
VAE 모델 ae.safetensors 을 다운로드 받은 후, ComfyUI\models\VAE 폴더에 넣어줍니다.
2 단계: 워크플로 불러오기
아래의 Json 파일을 다운로드 받아 ComfyUI로 불러옵니다.
이 워크플로를 불러오면 오류가 발생할 수 있습니다. 그러한 경우, 다음과 같은 작업이 필요합니다. 특히, ComfyUI를 실행시키고 ComfyUI 버전이 0.3.43 이상인지 확인해 보세요.
- 처음 사용할 때 - ComfyUI Manager 를 설치해야 합니다.
- ComfyUI를 오랜만에 사용할 때 - ComfyUI를 최신버전으로 업데이트해야 합니다.
- 노드가 없다고 (빨간색) 경고가 뜰 때 - 빠진 커스톰 노드를 가져오기해야 합니다.
- 불러오기 혹은 수행중 에러 발생시 - 커스톰 노드를 업데이트해야 합니다.
3 단계: 이미지 불러오기
아래와 같이 [Load Image] 노드에 원하는 이미지를 불러옵니다.
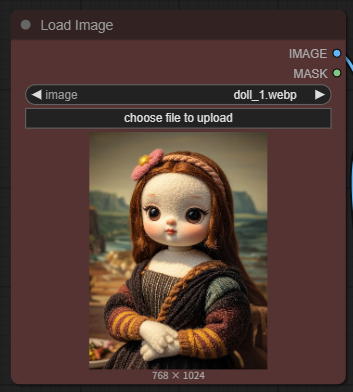 |
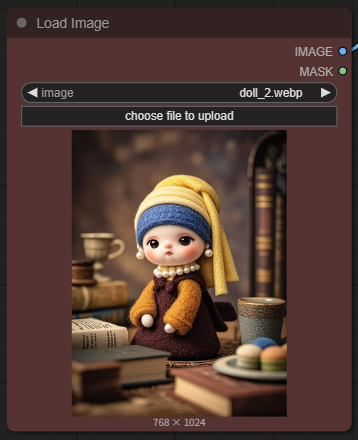 |
아래의 이미지를 사용하셔도 됩니다.
{kind=link}
{kind=link}
4 단계: 프롬프트 검토
이 워크플로는 여러 단계에 걸쳐 순차적으로 이미지를 생성하고 편집합니다.
- 1단계 : Place both cute 3D characters together in one scene where they are hugging (두 캐릭터가 서로 끌어안고 있는 모습 생성)
- 2단계 : Make both character smiling (캐릭터를 웃게 만드는 편집)
- 3단계 : Smooth the skin on both dolls' forehead(이마의 오톨도톨한 부분을 부드럽게 만드는 편집)
- 4단계 : Add a big white 3D style "ComfyUI" text in the bottom center of the image(이미지 중앙에 텍스트를 추가)
원하시면 프롬프트를 편집하셔도 되고, 뒷부분에 추가할 수도 있습니다.
5 단계:이미지 생성
이제 화면 오른쪽 위에 있는 Run 버튼을 누르면 워크플로가 실행됩니다. 아래는 입력 이미지와 출력 이미지를 비교한 것입니다.
아래는 이미지 스티치 결과입니다. 단순히 두 사진을 나란히 둔 겁니다.

1단계 수행 결과입니다. 두 3D 캐릭터가 잘 살아 있고, 껴안고 있는 모습도 잘 표현되었습니다.

2 단계 수행 결과입니다. 미소가 약간 부자연스럽기는 한데, 그래도 괜찮습니다. ㅎㅎ

3 단계 수행 결과입니다. 이마를 부드럽게 하는 명령이 뭔지 몰라서 몇번 시행착오를 겪었는데, 그런대로 잘 나왔습니다. 지금보니 오른쪽 인형의 관자놀이 부근에 약간 오톨도톨한 게 남아 있네요.

4단계 수행 결과입니다. 아래쪽에 글씨가 잘 새겨졌습니다. 그런데 사실 이렇게 결과를 얻기까지 한 10번 이상을 생성해야 했습니다. 계속 오타가 나와서요.

오바마와 김태리
위의 워크플로를 수정해가면서 생성한 이미지입니다.
 |
 |
1단계: Two people are standing shoulder to shoulder. The man has his hand on the woman's shoulder. Two people are smiling broadly.

2단계: Remove the letters in the lower right (오른쪽 아래의 글자들 삭제)

3단계: The woman on the left looks at the man on the right and smiles.(김태리씨가 오바마를 바라보며 웃는다) 아... 그런데 김태리씨의 얼굴이 확변해버렸네요. 동양인의 얼굴은 일관성 유지가 매우 힘들기 때문인데, 여러번 수행해도 고쳐지지 않아서 포기했습니다.

4단계: Sharpen photos while keeping people's identities and compositions intact, and eliminate JPEG defects.(사람들의 식별성, 구도는 변하지 않은 상태로 사진을 선명하게 하고 JPEG 결함 삭제)

5단계: Add a big white 3D style "ComfyUI" text in the bottom center of the image(이미지 중앙에 텍스트를 추가)

혹시 필요하시면 아래의 워크플로를 참고하세요.
워크플로 사용방법
위의 워크플로는 제가 다 시험을 끝낸 완성된 상태라서 한꺼번에 돌리면 원하는 결과를 얻을 수 있습니다(모든 씨드 번호가 고정(fixed)되어 있습니다). 하지만, FLUX.1 Kontext는 중간 결과물을 보면서 순차적으로 수정하는 것이 가장 좋습니다.
따라서 맨처음 돌릴 때는 맨 왼쪽에 있는 [FLUX.1 Kontext Image Edit] 노드 하나만 활성화시키고, 나머지는 모두 Bypass 시킨 상태로 수행하고, 원하는 결과가 나올 때마다 그 오른쪽의 노드를 켜고 프롬프트를 수정한 뒤에 실행시켜서 만족할 때까지 반복하고.... 이런 식으로 단계별로 수행하시면 됩니다.
이때 프롬프트에 한꺼번에 여러가지 내용을 넣는 것 보다, 여러 단계로 나누어 편집하시는 게 좋습니다. 자세한 내용은 여기를 읽어보시기 바랍니다.
참고
제 3070ti 컴퓨터에서 이 워크플로를 수행하는데 이미지 4장을 생성하는 시간까지 포함해서 총 17분 23초가 소요되었네요. 사실은 계속 수정을 하면서 생성해야 해서 훨씬 더 많은 시간이 걸릴 걸 감안하시고 작업하셔야 합니다.
이 워크플로는 아래와 같이 하나의 노드에 모델 불러오기와 프롬프트와 샘플링까지 모든 단계를 포함한 [FLUX.1 Kontext Image Edit] 노드를 사용하여 만들어졌습니다. 그래서 쉽게 새로운 단계를 추가할 수 있어 편리합니다. 다만... 이렇게 실행 속도가 많이 걸리다보니, TeaCache를 추가할 수 없어서 좀 아쉽네요.

이상입니다.
이 글은 comfyui FLUX.1 Kontext dev 튜토리얼의 글을 참고로하여 작성했습니다.
민, 푸른하늘
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 투토리얼
- ComfyUI를 위한 유용한 정보
- ComfyUI와 SDXL 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)