ComfyUI는 다재다능한 오픈소스 이미지 생성형 AI인 스테이블 디퓨전을 위한 GUI중 하나입니다. 원래는 AUTOMATIC1111이 훨씬 더 많이 사용되었지만, 여러가지 워크플로를 쉽게 생성하고 변경할 수 있어서 사용자가 급격하게 늘어나는 중입니다.
다만, ComfyUI는 스테이블 디퓨전의 기술적인 내용과 많은 관련이 있어서 사용하기가 쉽지 않습니다. 요즘 들어 ComfyUI 에 관한 글이 더 많아졌는데, 사용법이 잘 정리된 문서가 없어서 고민하던 중이었는데, 이 투토리얼은 아주 기초적인 내용부터 고급 사용법까지 아우르는 여러가지 내용을 담고 있습니다. 처음부터 따라해보면 ComfyUI를 좀 더 확실하게 이해하실 수 있게 될 것입니다.
이 투토리얼은 Open.ai 의ComfyUI Academy에 올려진 11개의 유튜브 내용을 나름 편집해 정리한 것입니다. 따라서 이 글을 읽으신다면 해당 유튜브를 보면서 읽는 것을 추천드립니다.
이 튜토리얼은 모두 세편으로 이루어져 있습니다.
- ComfyUI 튜토리얼-1: 유튜브 1~4편
- ComfyUI 튜토리얼-2: 유튜브 5~8편
- ComfyUI 튜토리얼-3: 유튜브 9~11편
아래는 이 글의 목차입니다.
레슨 9 : ComfyUI에서 ControlNet 사용법
유튜브는 여기를 보세요~
아래는 ControlNet 을 사용하는 워크플로입니다. 윗부분은 콘트롤넷을 사용해 이미지를 생성하는 부분이고, 아래는 여러가지 ControlNet 전처리기(Preprocessor)의 효과를 보기 위한 부분입니다.
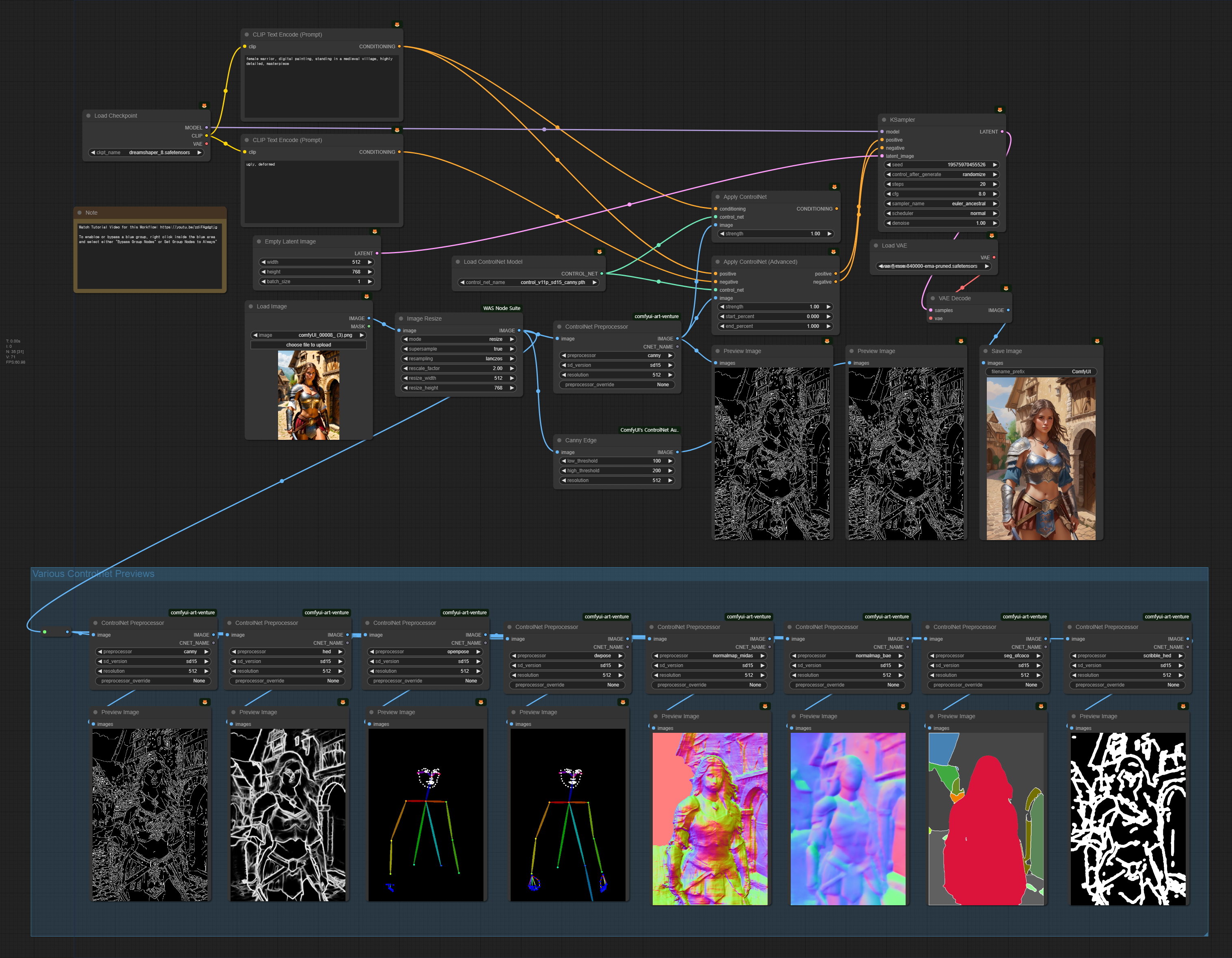
아래는 이 글에서 사용하는 이미지입니다.

일반적인 ControlNet 사용법
ControlNet은 참조 이미지의 자세와 구도를 복사하여 새로운 이미지를 만드는, Stable Diffusion에서 매우 중요한 모델입니다. 즉, ControlNet을 이용하면 참조 이미지와 비슷하지만, 다른 스타일의 이미지를 생성할 수 있습니다. ComfyUI에서 콘트롤넷을 사용하는 방법은 여기를 참고하시기 바랍니다.
아래는 위의 워크플로를 사용해 생성한 이미지입니다. 맨 왼쪽은 원본 이미지이고, 나머지 두개는 생성한 이미지입니다. 이 경우네는 외곽선을 추출하는 Canny 알고리즘을 사용했기 때문에 구도가 거의 동일하고, 색감이나 스타일만 약간 다릅니다.
 |
 |
 |
아래는 위 워크플로에서 ControlNet을 사용하기 위한 가장 핵심적인 부분만 따로 떼어낸 것입니다.

왼쪽에 참조 이미지는 [ControlNet Preprocessor] 노드에 들어가 전처리를 거쳐 새로운 이미지가 만들어집니다. 여기에서는 외곽선이죠. 이 이미지는 [Apply ControlNet] 또는 [Apply ControlNet (Advanced)]에서 사용되고 최종적으로 [KSampler]로 들어가게 됩니다. [Apply ControlNet] 또는 [Apply ControlNet (Advanced)]에는 전처리 이미지에 맞는 콘트롤넷 모델을 [Load ControlNet Model]에 입력해야 하고요.
[Apply ControlNet] 와 [Apply ControlNet (Advanced)]는 여러가지 차이가 있지만, 가장 중요한 것은 start_percent와 end_persent 입니다. 즉, 콘트롤넷을 언제 적용하기 시작해서 언제 끝날지를 지정할 수 있는 것입니다. 이 두가지 모두 적절하게 조절하면 ControlNet의 효과를 줄일 수 있는데, 잠재 이미지의 잡음은 거의 초기에 결정되기 때문에 start_percent설정이 더 중요하다고 할 수 있습니다.

따라서 콘트롤넷의 구도를 따르지만, 사용한 모델의 스타일을 반영하고 싶다면, start_percent는 0으로 고정하고, end_percent를 0.3 과 같이 낮추면 효과를 볼 수 있습니다. 맨 오른쪽은 0.2까지 낮춘 결과로 자세와 스타일이 완전히 달라지네요. 이를 활용하면 비슷한 구도이면서 색다른 스타일을 만들어볼 수 있어 매우 유용합니다.
 |
 |
 |
| start=0, end= 0.5 | start=0, end= 0.3 | start=0, end= 0.2 |
참고로 이 워크플로에서 [KSampler]노드의 잡음 제거 강도(denoise)는 1.0 으로 설정되어 있는데도, 입력된 이미지와 거의 같은 이미지가 생성되었습니다. img2img의 경우에 denoise를 1.0 으로 설정했다면 완전히 다른 이미지가 생성되었을텐데 말이죠. 이 처럼 비슷한 스타일과 구도를 유지 하려면 img2img보다 콘트롤넷이 더 유용함을 알 수 있습니다.
전처리기(Preprocessor)
위의 워크플로 아래쪽에는 다양한 전처리기의 효과를 볼 수 있습니다. 전처리기가 어떤 종류가 있고, 어떤 데 사용하는게 효과적인지 하는 내용은 이 글을 읽어보시기 바랍니다.
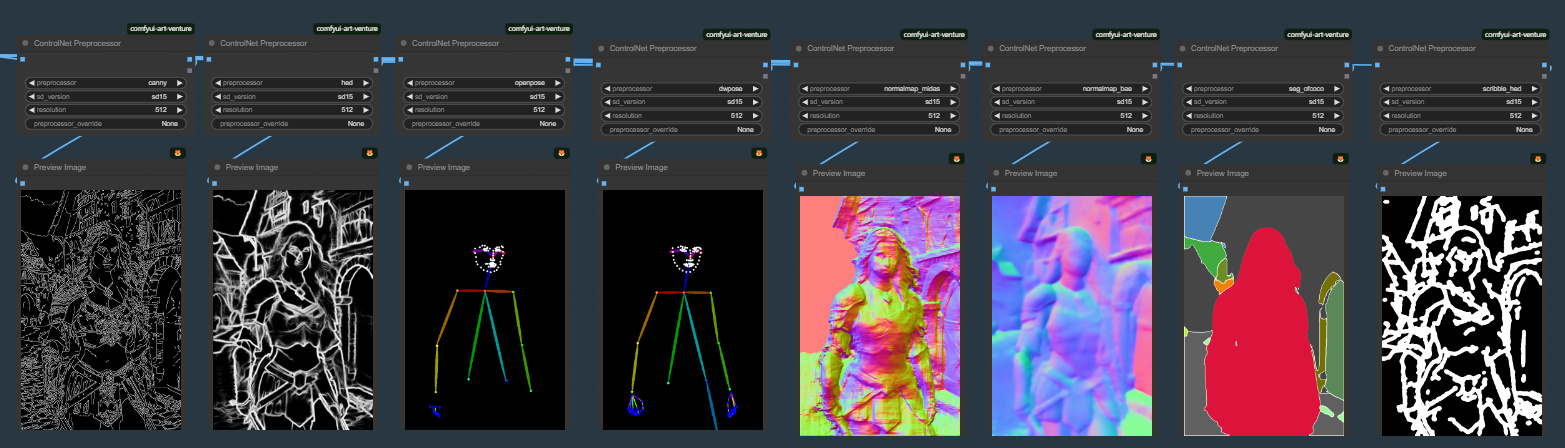
이 워크플로 가운데에는 전처리기가 두개 들어 있습니다. 하나는 [ControlNet Preprocessor] 노드이고, 다른 하나는 [Canny Edge] 노드입니다. 이름에서 알수 있는 것처럼 [ControlNet Preprocessor] 노드는 범용 노드로, 원하는 전처리기를 선택해서 사용할 수 있는데 비해, 두번째는 각각의 모델에 따른 전용 노드입니다.

즉 [Canny Edge] 노드는 Canny 전처리만 가능하며, [Openpose Pose] 노드는 openpose 만 처리하는 등입니다. 물론 전용 노드는 더 많은 옵션이 있어 보다 세밀하게 제어할 수 있으므로 편하신대로 골라 사용하면 됩니다.
레슨 10 : UltimateSDUpscaler
유튜브는 여기를 보세요~
Upscaler가 필요한 이유
UltimateUpscaler 는 말그대로, 확대에 진심인 모델입니다. 기본적으로 더 작은 이미지(기본 512x512)로 잘라서 각각을 확대한 후 다시 합치는 방식입니다.
SD1.5 의 경우, 기본 이미지 크기가 512x512로 너무 작아서, 어쩔 수 없이 확대가 필요했습니다. 기본 이미지 크기가 1024x1024인 SDXL이 나오면서 확대의 필요성이 낮아지긴 했지만, 그래도 요즘의 모니터 해상도를 생각해보면 2~3 배 정도는 확대해야 전문적인 분야에 활용할 수 있으니 확대는 불가피하다고 할 수 있습니다.
문제를 더 복잡하게 만드는 것은 스테이블 디퓨전으로 생성된 복잡한 장면이 선명하지 않은 경우가 많다는 점입니다. 즉, 전반적인 이미지의 형태는 괜찮은 것 같아도, 자세히 들여다 보면 세밀한 디테일이 표현되지 않는 경우가 많다는 것입니다. 이러한 경우, AI 이미지 확대기(Upscaler)를 사용해야 합니다.
Upscaler에 관한 좀 더 자세한 사항은 이 글을 읽어보시기 바랍니다.
UpScaler 워크플로
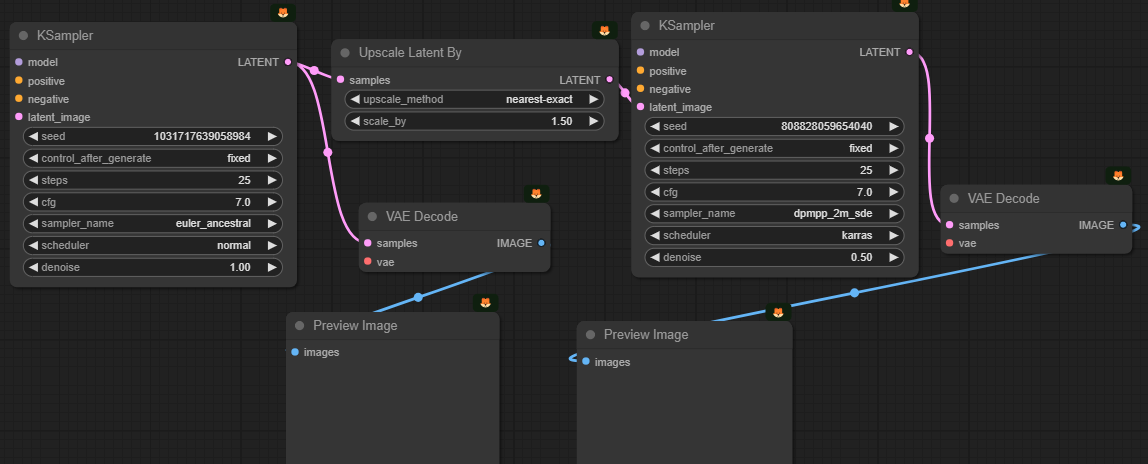
아래는 이미지를 생성하고, 생성된 결과를 HiRes Fix 로 확대한후, 다시 UltimateSDUpscaler로 확대하는 워크플로입니다.

이 워크플로에서는 [KSampler] 노드가 여러번 사용되고 있습니다. 아래는 그중 첫번째로 이른바 "HiRes Fix" 프로세스입니다. 한번 생성된 이미지를 확대해서 다시한번 샘플링하여 이미지의 품질을 높이는 기술입니다. SD 1.5에서는 거의 필수적이라고 할 수 있죠. 잘 살펴 보시면 첫번째 [KSampler] 노드와 두번째 [KSampler]노드는 다른 샘플러를 사용하며, 두번째 [KSampler] 노드의 경우 잡음 제거 강도(denoise)를 0.5로 두어 원본을 유지하면서도 여러가지 변경이 가능하도록 설정하고 있습니다.
아래는 위의 프로세스에서 생성되는 이미지를 비교해본 것입니다. 대충보면 거의 비슷해보이지만, 자세히 살펴보면 디테일이 많이 차이남을 알 수 있습니다. 이처럼 ComfyUI에서는 언제든지 중간 이미지를 확인할 수 있어 편리합니다.
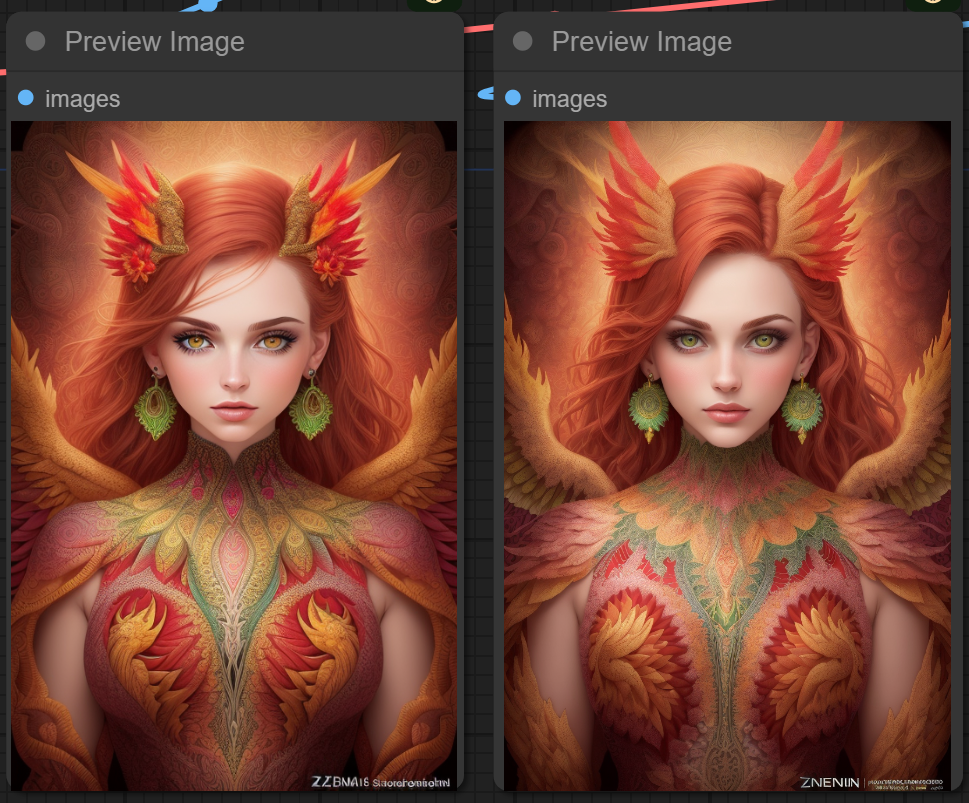
특히, 이 워크플로처럼 여러 단계를 걸치고, 최종 결과물이 생성될 때까지 시간이 많이 걸리는 프로세스의 경우, 씨드 값을 고정시킨 상태에 중간 결과물을 보며 마음에 안들면 중간 작업을 취소시키는 방법이 좋습니다. 그 다음 다른 씨드 값을 적용하여 다시 작업을 확인하는 과정을, 마음에 드는 중간 결과물이 얻어질 때까지 반복하고, 그 다음 단계로 넘어가면 최소한의 시간 낭비는 줄일 수 있습니다.
이렇게 생성된 이미지는 다음으로 [ImageSharpen] 노드를 통해 샤프닝을 적용합니다. 이렇게 하면 UltimateDetailer 적용과정에서 보다 디테일이 살고 선명한 이미지를 얻을 수 있다고 합니다. 원하시면 sigma 나 alpha값을 조정해서 샤프닝 정도를 수정할 수 있습니다.
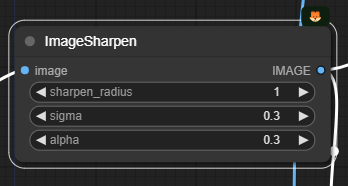
마지막으로 [UltimateSDUpscale] 노드입니다. 보시는 것처럼 매개변수가 매우 많습니다. 하지만 거의 대부분 건드릴 필요는 없이 기본 값으로 사용해도 무방합니다.
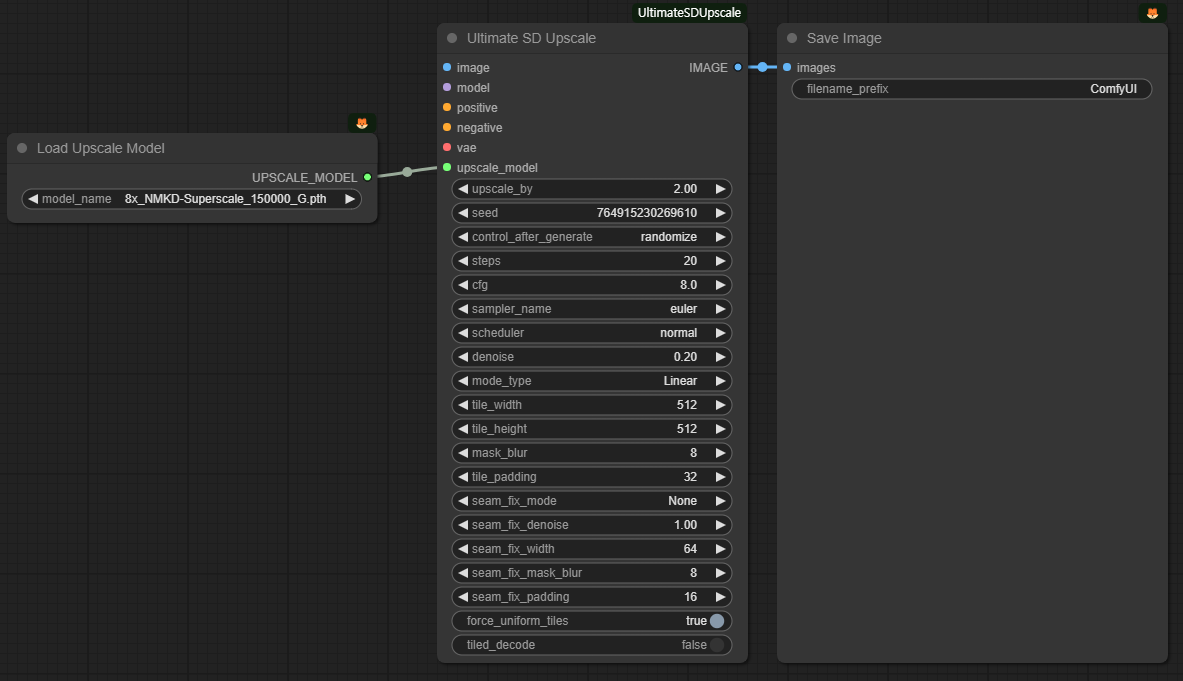
주의해야 할 매개변수는 아래와 같습니다.
- upscale_by (2) : 확대비율입니다. 원하시는대로 설정하면 됩니다. 1로 설정하면 동일한 크기로 UltimateSDUpscale 모델만 적용하게 됩니다.
- denoise (0.2) : 잡음 제거 강도입니다. 0~1사이로 설정할 수 있는데, 높을 수록 이미지의 변화가 많아집니다.
- tile_width, tile_height (512x512) : 한번에 처리하는 이미지 크기입니다.
- seam_fix_xxxx : 이미지 타일간의 접합부를 처리하는 방식을 결정합니다.
결과적으로 이 워크플로를 거치면 처음에 512x768 짜리 이미지가 HiRes Fix를 거치며 768 x1152(1.5배)로 확대되고, 마지막으로 UltimateSDUpscale 을 거쳐 1536x2304(2배)로 확대 됩니다.
Upscale 모델
위의 왼쪽에는 [Load Upscale Model] 노드에서 확대(Upscale)을 위한 모델을 불러들입니다. 이러한 모델들은 ComfyUI Manager를 사용해 설치할 수 있습니다. 아래와 같이 ComfyUI Manger Menu에서 [Install Models]를 선택하면 됩니다. 참고로 AUTOMATIC1111 의 경우 Upscale 모델은 "stable-diffusion-webui\models\ESRGAN" 폴더에 저장하면 됩니다.

아래는 upscale 용 모델만 모아본 것입니다. 모델명을 보면 4x, 8x와 같이 배율이 정해져 있는 것처럼 보이지만, 이는 아무런 효과가 없으며 배율에 관계없이 사용할 수 있습니다. 다만, 여기에는 없지만, 1x로 표시된 모델의 경우엔 확대엔 사용하지 않고 이미지 품질을 높이는 용도로만 사용할 수 있습니다. 이 모델을 사용한다면 [UltimateSDUpscale] 노드를 두개 이상 연속해서 사용하는 것도 괜찮겠네요.
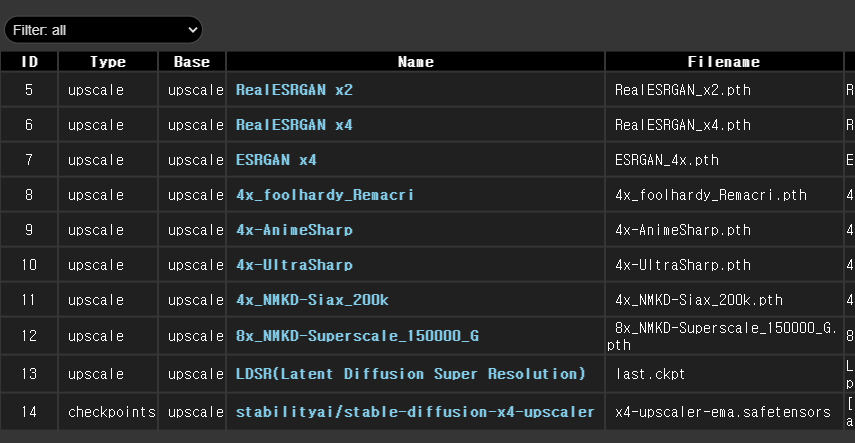
또한 https://openmodeldb.info/ 에 들어가면 여러가지 용도의 Upscaler가 많으니 참고하세요.
아래는 최종적으로 생성된 이미지입니다. 1536x2304 크기네요. 멋집니다.

레슨 11 : Face Detailer
유튜브는 여기를 보세요~
Face Detailer가 필요한 이유
스테이블 디퓨전으로 이미지를 생성하면, 특히 SD 1.5의 경우 얼굴 크기가 작은 인물이 있으면 얼굴은 대부분 이상하게 생성됩니다. 이것을 수정하기 위한 가장 기본적인 작업은 inpaint라고 할 수 있습니다. 마음에 안드는 부분만 새로 그리면 대부분 해결되니까요.
하지만, 얼굴 크기가 작은 경우, 아무리 inpaint를 반복해도 원하는대로 잘 안되는 경우가 많습니다. 스테이블 디퓨전이 작은 얼굴을 제대로 학습하지 못했기 때문입니다.
Face Detailer는 이미지 생성중에 자동적으로 얼굴 부분을 찾아 확대한 후 새로 그리는 방식으로 얼굴을 개선하는 방식입니다. AUTOMATIC1111의 경우, After Detailer 확장에서 Face Detailer와 동일한 작업을 합니다. 자세한 내용은 이 글을 읽어보시기 바랍니다.
Face Detailer 워크플로
아래는 HiRes.Fix와 Face Detailer 가 포함된 워크플로입니다.
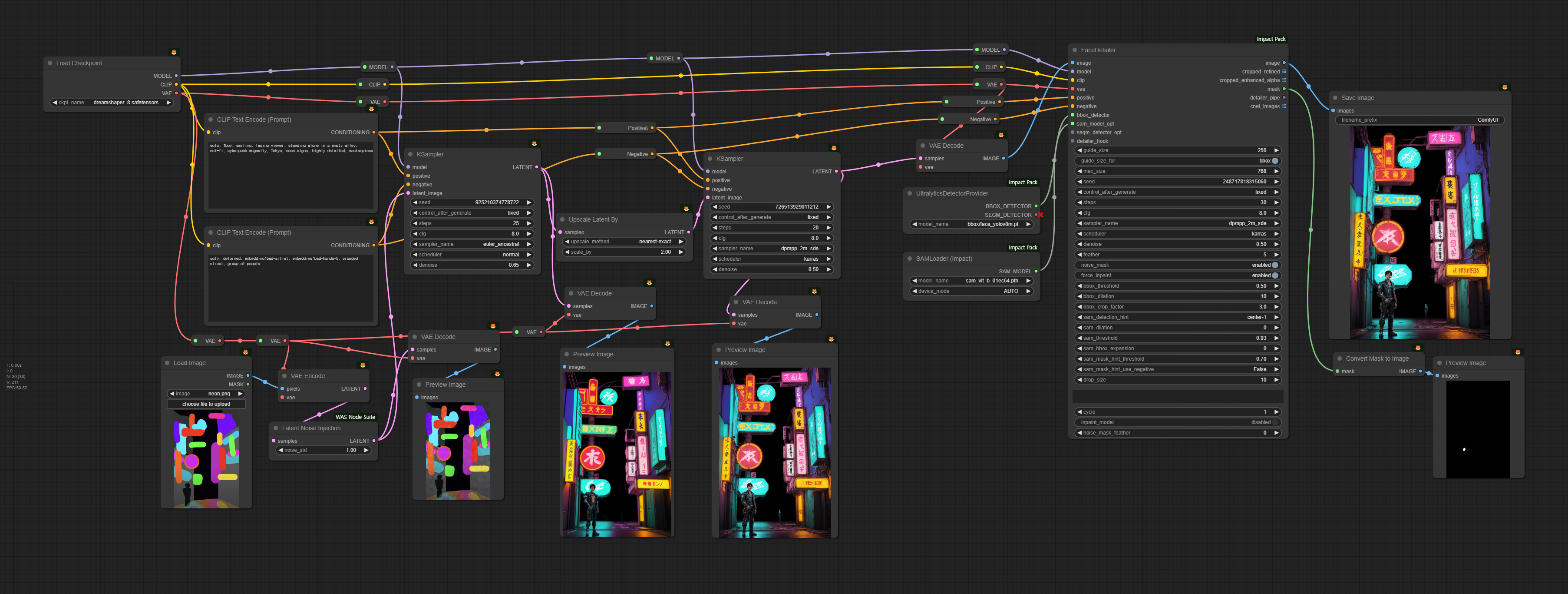
입력이미지에 노이즈 추가
이 워크플로의 좌측 하단은 img2img를 위한 이미지를 입력하는 부분입니다. 아래의 이미지를 사용합니다. 도쿄의 네온 사인을 표현하기 위해서 다양한 형광색을 사용했습니다. 그리고 사람이 서있을 부분은 왼쪽 아래에 작게 지정했습니다.

그냥 이 이미지를 넣을 수도 있지만, 여기에 노이즈를 추가합니다. 노이즈를 추가하면 이미지 생성시 보다 더 디테일이 살아난다고 합니다. (제가 알기론 add_detail LoRA가 이와 비슷한 역할을 하는 걸로 압니다만..ㅠㅠ) 어쨌든...
원래 워크플로는 아래처럼 생겼습니다. 위의 이미지와 청색 바탕에 분홍색 노이즈가 있는 이미지를 합쳐서 노이즈가 있는 영상을 만들어 이를 [KSampler] 노드의 입력 이미지로 사용했습니다.
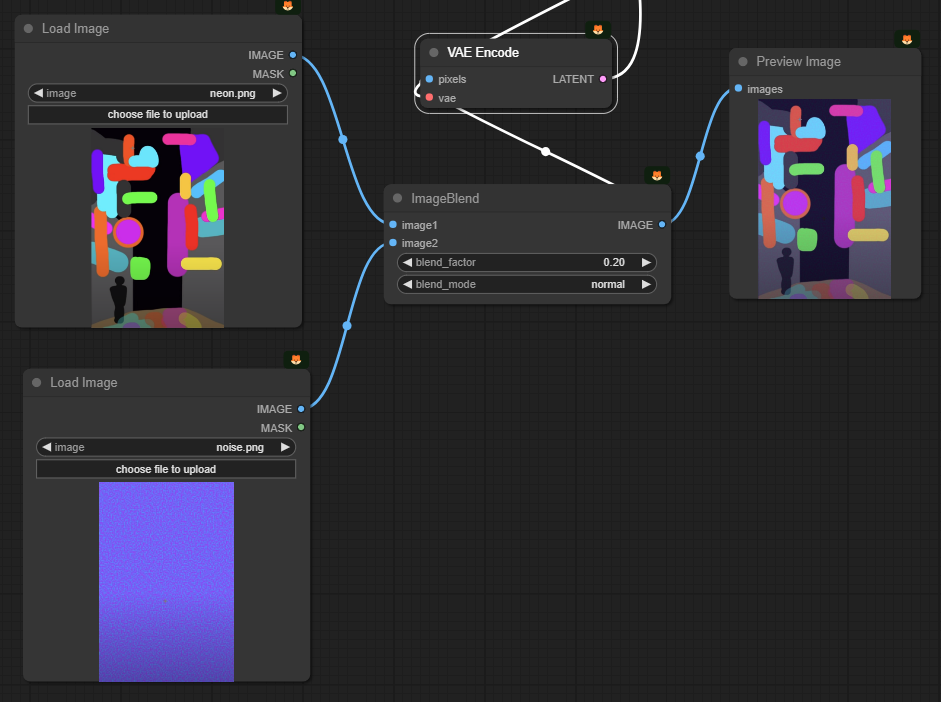
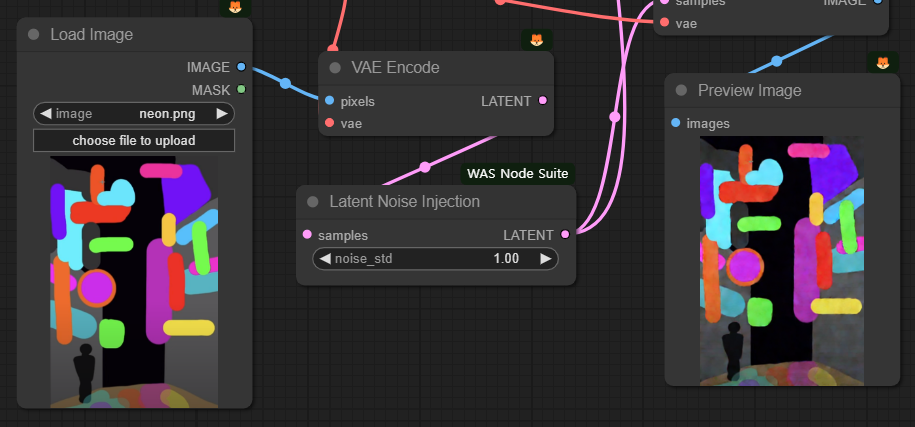
그런데 저는 이게 너무 못마땅했습니다. 구지 노이즈까지 별도의 이미지로 만들어야 하나... (유튜브 제작자는 포토샵같은 걸 이용해 만들었다고 하더군요) 싶어서 Noise를 추가해주는 [Latent Noise Injection] 노드를 찾아서 노이즈를 추가해주는 방식으로 변경했습니다.
얼굴 복원
다음은 매번 당연하게 들어가는 HiRes. Fix 프로세스입니다. 위에서 입력된 이미지를 사용하여 img2img 방식으로 이미지를 생성하고, 이를 2배로 크게 만들어 다시 [KSampler]를 돌렸습니다.

아래는 이 프로세스를 통해 만들어진 이미지의 사람 부분만 비교한 것입니다(좌측은 Upscale 전으로 비교를 위해 2배로 확대했습니다). 보시는 것처럼, 이미지 전체가 디테일이 많이 추가되었음을 알 수 있습니다. 얼굴도 상당히 좋아졌습니다.
 |
 |
참고로 유튜브를 보시면 얼굴이 그다지 좋아지지 않았습니다. 제가 볼 때 그 이유는 두번째 [KSampler]의 잡음 제거 강도를 0.35로 낮게 두어서 원본 이미지의 상태가 그대로 반영되었기 때문이 아닌가 하고요, 저는 0.5로 설정하니 전반적으로 디테일이 좋아졌습니다.
또한, 유튜브에서는 HiRes. Fix 프로세스 다음에 [UltimateSDUpscaler] 노드를 넣어 더 확대했지만, 저는 이를 삭제해 버렸습니다.
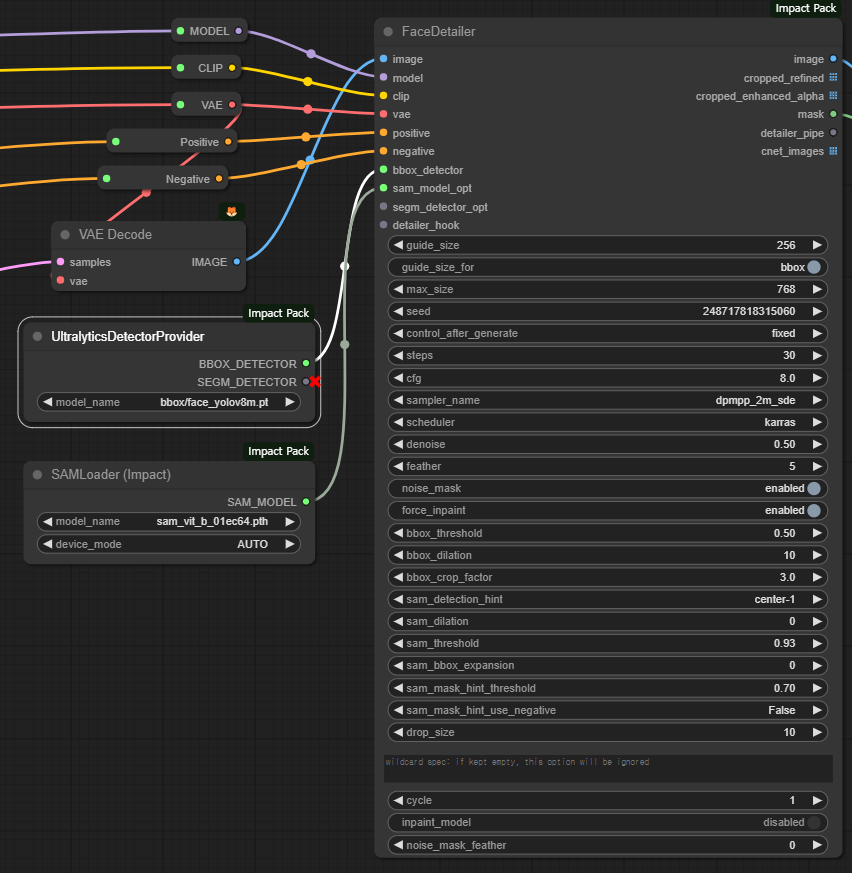
마지막으로 [Face Detailer] 노드입니다. 아래에서 보시는 것처럼 이 노드는 매우 많은 매개변수를 가지고 있어 한마디로 기가 막히게 만듧니다(대부분은 건드릴 필요 없습니다). 그럼에도 불구하고 두 개의 노드를 슬롯에 연결해 주어야 합니다. 하나는 [UltralyticsDetectorProvider] 노드와 [SAMLoader] 노드 입니다. 참고로 [UltralyticsDetectorProvider] 노드는 얼굴찾기에 최적화된 face_yolov8m.pt 모델을 사용하도록 설정되어 있습니다.
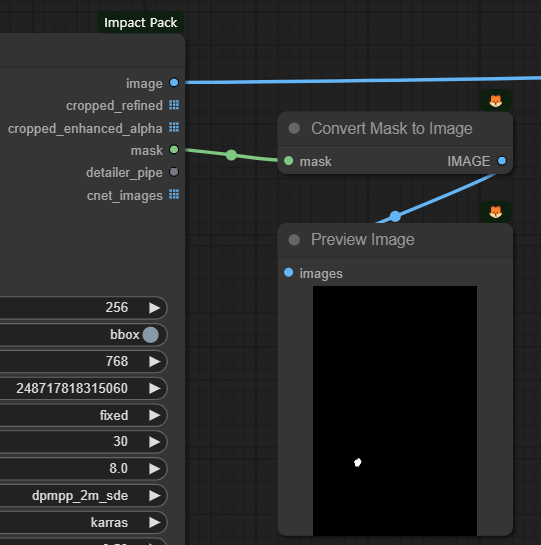
[FaceDetailer]노드 의 출력 슬롯중에는 mask가 있습니다. 이 마스크는 [UltimateSDUpscaler] 노드에서 찾아낸 얼굴 영역을 표시합니다. 그래서 이 마스크를 이미지로 변환해보니 얼굴의 위치가 잘 맞네요.
아래는 [FaceDetailer] 노드 전후를 비교해 본 것입니다. 아직까지도 얼굴 크기가 작아서 완벽하지는 않지만, 그래도 꽤 괜찮은 수준까지 얼굴이 복원된 것을 볼 수가 있습니다.
 |
 |
참고로 아래는 [UltimateSDUpscaler] 노드를 지우지 않은 상태로 생성한 이미지입니다. 여기선 얼굴이 확실하네요. ㅎ 하지만 이미지 크기 자체가 다르니... 제가 수정한 프로세스에서도 이미지 크기를 더 키우면 좋은 결과가 나오지 않을까 생각해봅니다.

이상입니다. 이 글은 OpenArtFlow 의 ComfyUI Academy에 있는 유튜브 9~11편을 사용하여 제 마음대로 편집하여 작성하였습니다.
민, 푸른하늘
====
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 투토리얼
- ComfyUI를 위한 유용한 정보
- ComfyUI와 SDXL 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기