스테이블 디퓨전을 활용하는 이유중 가장 중요한 것중의 하나가 사실적인 인물 사진을 생성하는 것입니다. 카메라로 직접 현장에서 찍은 것같은 진짜처럼 보이는 사진. 이 글에서는 사진 스타일의 이미지를 생성하는 원리를 알아 보겠습니다. 프롬프트, 모델, 사진확대기 등이 이 글에서 다룰 주요 내용이다.
소프트웨어
스테이블 디퓨전을 사용하는 방법은 여러가지가 있습니다. 이 글에서는 AUTOMATIC1111을 사용하는데, AUTOMATIC1111 GUI는 윈도에서도, Mac에서도, Google Colab에서도 사용할 수 있습니다. 제 컴퓨터 그래픽 카드가 오래된 것이다보니, 저는 앞으로 Google Colab 환경을 주로 사용하기로 했습니다.
프롬프트
여기에서는 사실적인 인물 사진을 생성하기 위한 고품질의 프롬프트를 입력하는 방법에 대해서 알아보겠습니다. 먼저 레스토랑 밖에 앉아 있는 여자 사진을 생성하는, 아주 간단한 프롬프트로 시작해 보죠. 모델은 v1.5 기본 모델을 사용하겠습니다. (다운로드 링크)
프롬프트 : photo of young woman, highlight hair, sitting outside restaurant, wearing dress
모델 : Stable Diffusion v1.5 - v1-5-pruned-emaonly.ckpt
샘플링 방법 : DPM++ 2M Karras
샘플링 스텝수 : 20
무분류기 인네 척도(CFG, Classifier Free Guidance) : 7
이미지 크기 : 512x768
결과는 아래와 같습니다. 총 8장을 뽑았는데, 이상하지 않다 싶은게 하나도 없었습니다. ㅠㅠ
 |
 |
 |
누구도 이런 괴상한 이미지를 원하지 않겠죠. 이를 보완하기 위해 부정적 프롬프트를 넣어보겠습니다. 여기에선 아주 간단하게만, 해부학적 신체 구조가 이상한 것과 사실적이지 않은 스타일을 제외시키는 것이 목적입니.
부정적 프롬프트 : disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
아래가 그 결과입니다. 이번에도 총 8개의 이미지중에서 그나마 나은 것을 추린 것입니다.
 |
 |
 |
전체적으로 부정적 프롬프트가 없을 때보다는 나아진 편이지만, 그래도 자연스러운 이미지라고 보기는 힘들 것 같습니다. 특히, 상체는 거의 문제 없이 보이지만, 하체의 구조는 거의 대부분 이상한 포즈가 등장하고 있습니다.
조명(빛) 관련 키워드
사진사가 해야할 일 중 가장 중요한 것중 하나가 좋은 빛 환경을 만드는 것입니다. 빛과 조명 환경이 흥미로워야만 좋은 사진이 만들어지기 때문이죠. Stable Diffusion도 동일합니다. 기존의 프롬프트에 조명관련 키워드와, 촬영 각도를 제어하는 키워드를 추가해 보겠습니다.
프롬프트 : photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera
부정적 프롬프트 : disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
 |
 |
 |
훨씬 나아졌네요. 특히 상반신만 나온 이미지는 이 정도만으로도 충분히 눈을 즐겁게 해주는 사진이 나왔습니다. 하지만, 아직도 신체 구조가 이상한 사진은 계속 나오고 있습니다. 하지만, 걱정할 필요는 없습니다. 앞으로 이런 문제를 해결할 여러가지 방법을 알아보는 게 이 글의 목적이니까요.
카메라 키워드
DSRL, ultra quality, 8K, UHD 등의 키워드를 넣으면 이미지의 품질이 더욱 향상될 수 있습니다. 실제 사진의 경우, 좋은 카메라를 사용하면 좋은 사진이 나올 확률이 높으니까요(물론 기계보다 실력이 우선입니다).
프롬프트 : photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K, UHD
부정적 프롬프트 : disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
아래가 그 결과입니다.
 |
 |
 |
여기에서는 그다지 좋아지지는 않은 것 같습니다. 그렇다고 새로 추가한 프롬프트가 악영향을 미친 것 같지는 않고요.... 아마도 조명 관련 키워드에서 이미 전문가적 사진이라는 조건이 이미 반영되었기 때문에, 눈에 띄는 변화가 없는게 아닐까 생각합니다. 그래도 기분상 일단 넣어두는 게 낫지 않을까.... 하는 생각입니다.
열굴에 대한 상세한 묘사
마지막으로, 눈과 피부를 묘사하기 위한 감미료? 로서 몇가지 키워드를 소개하겠습니다. 이들 키워드를 사용하면, 좀더 사실적인 얼굴을 생성하는데 도움이 됩니다.
- highly detailed glossy eyes
- high detailed skin
- skin pores
다만, 이런 키워드를 사용할 경우, 피사체가 카메라에 가까워지는 부작용이 발생합니다. 근접 인물 사진에 이런 키워드를 많이 사용하니까요. 이들 키워드를 추가한 최종 프롬프트는 아래와 같습니다.
프롬프트 : photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K, UHD, highly detailed glossy eyes, high detailed skin, skin pores
부정적 프롬프트 : disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
위에서 말한 부작용처럼, 생성된 이미지가 모두 상반신 혹은 그 이상 확대된 사진들이 주로 생성되었습니다.
 |
 |
 |
지금까지 기본 모델만으로 어디까지 생성할 수 있는지를 알아보았습니다. 아직 특별한 Photo-realistic한 모델도 사용하지 않았음에도, 적어도 몇몇 이미지는 상당히 전문가적 느낌이 나는 이미지가 생성되었습니다. 하지만, 아직 시작일 뿐입니다.
얼굴 제어
두가지 얼굴 섞기
이미지 생성형 인공지능을 사용하는 것의 문제점중 하나가, 각 사진별로 다른 사람이 생성된다는 것입니다. 하나의 모델을 기반으로 여러 다른 포즈 또는 다른 구도로 이미지를 생성하는 것은 쉽지 않습니다. 여기에서는 이러한 방법을 고민해 보겠습니다.
우선 유명인(celebrity) 이름을 사용하는 방법입니다. 학습된 데이터에는 유명인의 이름이 포함되어 있으며, 이들의 얼굴은 일반적으로 일관성있게 생성됩니다. 그렇다고, 이들의 얼굴을 그대로 이용하는 것은 원하는 바가 아니겠죠. 너무 알려진 얼굴이라서 문제가 발생할 가능성도 크기 때문입니다. 따라서 여러 얼굴을 섞어서 특별한 특징을 갖는 새로운 얼굴을 만드는 방법이 유용할 것입니다.
이 방법은 두개의 얼굴을 프롬프트 스케줄링을 이용해 섞는 방법입니다. AUTOMATIC1111에서는 다음과 같이 프롬프트를 입력합니다.
[person 1 :person 2: factor]
여기서 factor(비율)은 0부터 1 사이의 값인데, 키워드가 person1에서 person2로 넘어갈 때 총 단계수 중 비율을 의미합니다. 예를 들어 샘플링 단계(Sampling steps)가 20이고 프롬프트에 [Ana de Armas:Emma Watson:0.5]를 추가할 경우, 1-10 단계에서는 아나 데 아르마스를 사용하고, 11-20단계에서는 엠마 왓슨을 사용한다는 의미입니다.
이제 위에서 사용해왔던 프롬프트에 이를 추가해 보겠습니다.
프롬프트 : photo of young woman, [Ana de Armas:Emma Watson:0.5], highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K, UHD, highly detailed glossy eyes, high detailed skin, skin pores
부정적 프롬프트 : disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
아래가 그 결과입니다. 워낙 엠마 왓슨의 얼굴이 특징이 강해서 좀 더 두드러지게 나타난 듯 싶네요.
 |
 |
 |
맨 마지막 사진을 보면 알겠지만, 이상한 신체 구조 문제는 아직 해결되지는 않았습니다만, 만, 얼굴은 의도했던 대로 세 개의 이미지(사실은 8개를 생성했고, 그중 6개)는 거의 비슷한 얼굴이 유지되고 있는 것 같습니다. 비율(factor)를 잘 조정하면 원하는 얼굴을 만들어 낼 수도 있습니다.
하나의 이름을 섞기
한가지 명심할 것은, 유명인(celebrity)의 이름을 사용하는 순간, 배경과 구도가 극적으로 바뀐다는 점입니다. 이를 연관 효과(association effect)라고 하는데, 여배우들 사진은 수상식과 같은 특정한 환경과 연결되는 경우가 많기 때문입니다.
그런데, 전체적인 구도는 첫번째 구도에서 대부분 결정됩니다. 샘플링 단계중 시작되는 부분에서 대부분의 노이즈가 제거되기 때문입니다. 이러한 점을 활용하는 방법으로서, 시작 단계에서는 woman이라는 키워드를 사용하고, 나중에 유명인 이름을 추가하는 방식이 유용할 수 있습니다. 이렇게 하면, 구도는 다양해지면서도 얼굴은 유명인의 얼굴이 어느 정도 반영됩니다.
프롬프트와 부정적 프롬프트는 아래와 같습니다.
프롬프트 : photo of young woman, [woman:Emma Watson:0.5], highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K, UHD, highly detailed glossy eyes, high detailed skin, skin pores
부정적 프롬프트 : disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
아래는 factor를 각각 0.3, 0.5, 0.7로 부여한 결과입니다. (씨드 번호 : 2368026957) factor를 크게하면 앞쪽 키워드의 영향이 커지므로, 오른쪽으로 갈 수록 엠마 왓슨의 느낌이 덜해지는 걸 알 수 있습니다.
 |
 |
 |
| 0.3 | 0.5 | 0.7 |
이 기법을 사용하면 구도는 유지하면서도 얼굴은 어느정도 유지시킬 수 있습니다. 유용하게 활용할 수 있을 것 같습니다.
얼굴 인페인트(Inpainting faces)
인페인트를 사용하면 구도를 유지하면서도 얼굴을 원하는 대로 바꿀 수 있습니다.
txt2img 탭에서 얼굴을 생성한 후, 바로 Send to inpainting을 누릅니다. 그러면 해당 얼굴이 img2img탭의 inpaint로 들어가고, txt2img에서 입력했던 프롬프트도 함께 전해지게 됩니다. (이때 프롬프트는 유명인 이름을 사용하기 전인 "photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K, UHD, highly detailed glossy eyes, high detailed skin, skin pores"을 사용했습니다.)

inpaint 캔버스에서 얼굴 부분을 마스크(mask) 씌워줍니다.
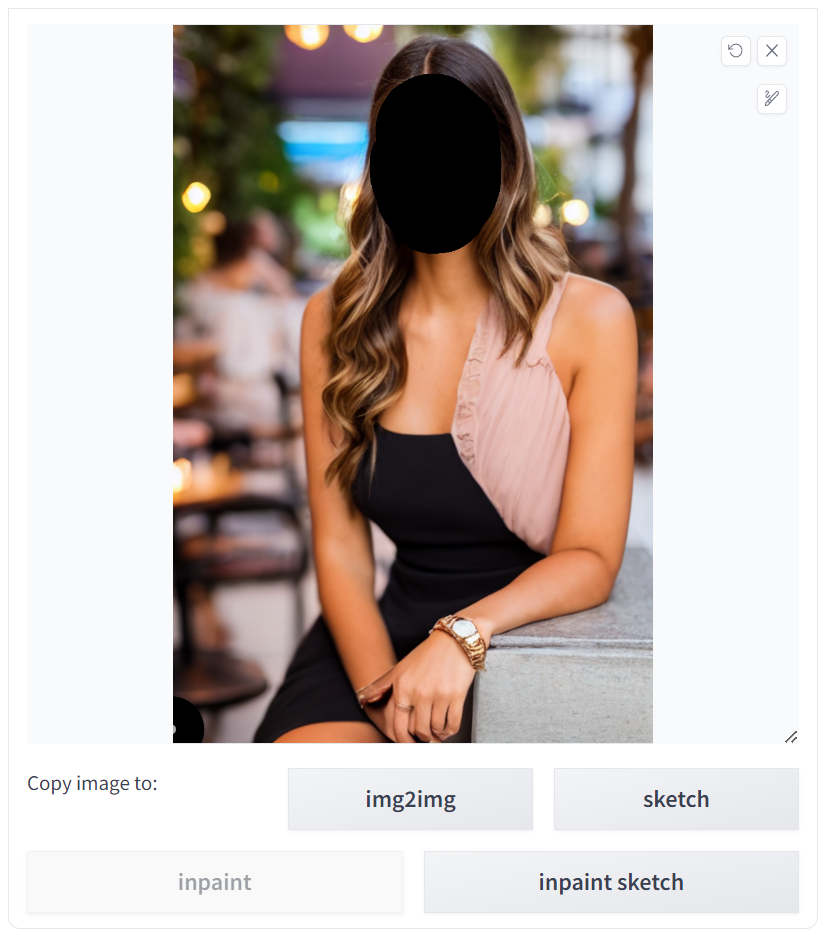
이제 유명인의 이름을 섞어보겠습니다.프롬프트는 다시 아래와 같은 형태로 됩니다. 다만, 그림 아래에 표시한 것처럼, 셀레브러티 이름은 다양하게 테스트해 보았습니다.
프롬프트 : photo of young woman, [Ana de Armas:Emma Watson:0.4], highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K, UHD, highly detailed glossy eyes, high detailed skin, skin pores
부정적 프롬프트 : disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
이때 잡음 제거 강도(Denoising Strength는 기본 값인 0.75로 두었으며, 배치 사이즈는 4로 설정한 후 가장 좋은 것을 선택했습니다.
 |
 |
 |
| [Ana de Armas:Emma Watson:0.4] | [Amber Heard:Emma Watson:0.5] | [Anna Kendrick:Liza Soberano:0.4] |
한가지 언급할 것은, 최종 생성된 이미지가 마스크 부분만 변경된 것이 아니라, 이에 영향을 받는 주변부도 변경된다는 점이다. 위 사진에서 모델의 왼쪽 어깨를 보면 머리카락과 옷의 형태가 약간씩 변화되었음을 알 수 있을 것이다. (inpaint 옵션중, inpaint 지역을 전체사진(whole picture)로 할지, 마스크가 칠해진 부분만(only masked) 칠할 지 지정할 수 있습니다. 전체사진이 기본입니다.)
결함 수정
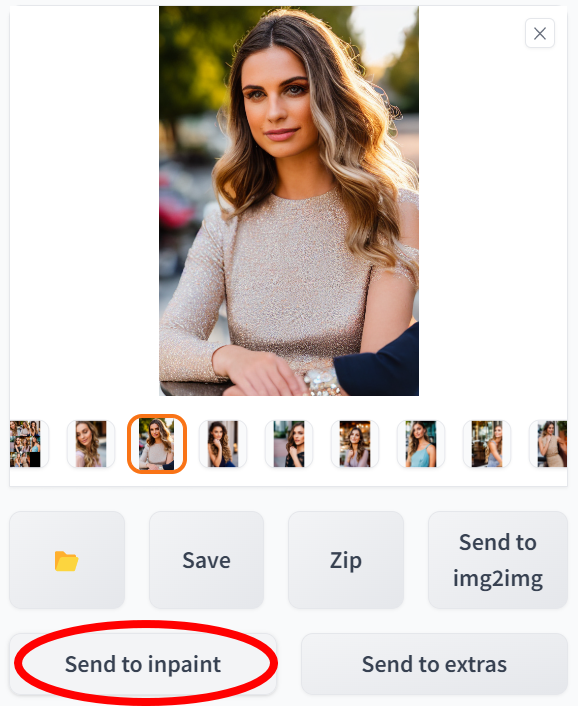
맨 처음부터 사실적인 인물을 생성할 필요는 없습니다. 이미지의 일부를 쉽게 재성성할 수 있기 때문입니다. 아래의 예를 살펴보죠. 팔이 세개나 되는데, 특히 남자의 손이 끼어들었네요. 이번에도 "Send to inpaint" 를 클릭하면, 이미지과 여러가지 파라미터가 img2img 탭으로 전달됩니다.
결함이 있는 곳을 마스크로 가려보겠습니다.
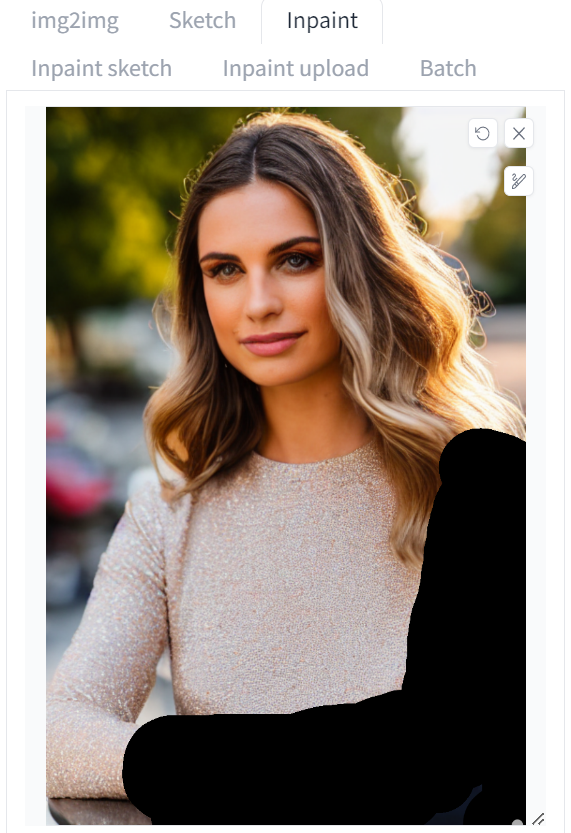
이때 씨드 번호는 -1(임의로), 잡음 제거 강도(denoising strength)는 1로 두고 이미지 생성량은 가능한 한 최대로 하 [Generate] 버튼을 눌러줍니다. 결함이 있는 이미지가 여전히 생성되겠지만, 일부는 괜찮은 것이 있을 수 있고, 없다면 다시 [Generate] 버튼을 누르면 됩니다.
그리고 전체적으로는 좋아졌는데, 그중 일부만 결함이 있다면 그 이미지를 다시 inpaint로 보내고 그 일부분에 대해서만 다시 마스크를 적용하는 방식으로 계속 반복할 수 있습니다. 점점 괜찮아진다고 싶다고 하면 잡음 제거 강도를 약간 더 낮춰줄 수도 있고요.
그런데... 결론적으로 실패했습니다. 아래쪽에 왜 파란색 양복? 이 나타나는지는 잘 모르겠지만, 여러번 돌려봐도 없앨 수가 없었습니다. 이 이미지 말고도 다른 이미지를 사용해서 여러번 시도해봤는데, 처음에 있었던 결함이 형태는 약간씩 다르지만 계속 나온다는 것만 확인했습니다.ㅠㅠ
이런 식으로 결함을 수정하는 것, 특히 확률에 의존해 신체적인 결함을 수정하는 것은 상당히 짜증 나는 일이 아닐 수 없습니다(다시는 할 생각이 없습니다). 그런데 다행히도, 아래를 읽어보면 알겠지만, 아얘 이런 신체적 결함이 발생하지 않도록 하는 더 좋은 방법들이 많습니다.
그래도 이 방법은 유용합니다, 해부학적 신체 구조 오류는 어떨지 몰라도 사소한 결함을 수정하는데는 Inpaint는 가장 손쉽고도 훌륭한 방법임을 기억합시다!!
모델(Model)
지금까지는 Stable Diffusion 1.5의 기본 모델만 사용하여 사실적 인물을 생성했습니다. 그런데, Stable Diffusion은 다른 모델을 사용할 수 있으며, 그중에는 특히 사실적 이미지를 생성하도록 학습된 모델들이 존재합니다. 이런 모델을 사용하면, 위에서 발생했던 여러가지 문제들이 훨씬 줄어듭니다. 아래는 널리 사용되고 있는 사실적 이미지용 모델들입니다.
- F222
- Hassan blend 1.4
- Realistic Vision v2
- Chillout Mix
- Dreamlike Photoreal
- URPM
물론 이것들 외에도 더 많을 수 있는데, 이해해주시기 바랍니다. 인공지능 세계는 하루하루가 다르게 바뀌어서 모든 걸 나열한다고 해봤자, 며칠 지나면 뒤떨어진 정보가 되어버리거든요.
이제부터 새로운 모델을 사용해 위와 비슷한 시도를 해보겠습니다. 우선 프롬프트는 동일합니다.
프롬프트 : photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K, UHD, highly detailed glossy eyes, high detailed skin, skin pores
부정적 프롬프트 : disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
주의 사항
위에서 언급한 거의 모든 모델이 노골적인(후방주의, NSFW) 이미지를 많이 생성합니다. 이를 방지하기 위해서 프롬프트에 dress 와 같은 옷 관련 키워드를 넣고, 부정적 프롬프트에 nude, NSFS와 같은 키워드를 넣어주는 게 좋습니다.
프롬프트 : photo of young woman, comfortable clothing, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K, UHD, highly detailed glossy eyes, high detailed skin, skin pores
부정적 프롬프트 : disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w, nsfw, nude
F222
 |
 |
 |
F222은 아름다운 옷을 착용한 사실적인 인물을 생성해줍니다. (대략적인 느낌으로, Stable Diffusion 1.5 기본 모델보다 훨씬 낫습니다. 전신이 표현된 경우에도 신체적인 구조에 결함이 있는 경우가 30% 미만입니다.) 하지만, 안타깝게도 이 모델은 더 이상 개발이 안되고 있다.
Hassan blend 1.4
- 모델 페이지 : https://huggingface.co/hassanblend/hassanblend1.4
- 다운로드링크 : https://huggingface.co/hassanblend/hassanblend1.4/resolve/main/HassanBlend1.4_Safe.safetensors
 |
 |
 |
Hassan Blend v1.4는 상당한 양의 노골적인 이미지에 대해 세밀하게 조정되어 있다고 합니다. (즉 누드 사진을 생성하는데 유용하다는 뜻입니다.) 하지만, 위 사진에서 보는 것처럼 일반 사진들도 매우 잘 생성합니다. 다만, 이 모델도 하체의 신체적 결함은 30% 정도 발생하는 듯하고, 동양인의 얼굴은 거의 나오지 않습니다.
Realistic Vision v2.0
- 모델 페이지 : https://civitai.com/models/4201/realistic-vision-v20
- 다운로드 링크 : https://civitai.com/api/download/models/29460
 |
 |
 |
Realistic Vision v2는 사진 스타일의 이미지를 생성하는데 다재다능하다고 합니다. 사실적인 인물 외에도 동물과 풍경 생성에도 훌륭하다고 하고요. 몇번 테스트 해보지는 않았지만, Realistic Vision 2.0을 사용하면 거의 신체적 결함이 있는 사진은 찾아보기가 힘든 것 같습니다. 다만, 16장의 이미지를 생성했는데, 얼굴이 상당히 비슷하네요... 어쨌든 실사 인물 사진을 생성할 때, 이 모델은 상당히 괜찮은 선택일 듯 합니다.
Chillout Mix
- 모델 페이지 : https://civitai.com/models/6424/chilloutmix
- 다운로드 링크 : https://civitai.com/api/download/models/11745
 |
 |
 |
ChilloutMix는 동아시아 여자들에 대한 F222라고 할 수 있습니다. 아무래도 저는 서양쪽보다는 동양쪽이 더 자연스럽게 느껴집니다. 사실적인(약간 아이돌 같은) 인물 사진을 잘 생성하고, 신체적인 결함이 있는 사진도 그다지 많이 생성되지 않습니다. 다만, 이 모델 페이지에 가보시면 알겠지만, NSFW한 사진도 많이 생성됩니다.
Dreamlink Photoreal
- 모델 페이지 : https://civitai.com/models/3811/dreamlike-photoreal-20
- 다운로드 링크 :https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0/resolve/main/dreamlike-photoreal-2.0.ckpt
 |
 |
 |
Dreamlike Photoreal은 다방면에서 사용가능한 사진 스타일 모델이라고 합니다. 다만 초상화 스타일 이미지가 약간 채도가 높은 경향이 있다고 하네요. 솔직히 저로서는 다른 모델들과 어떤 차이가 있는지 잘 느껴지지 않습니다. 그냥 서양인들이 많이 나온다 정도... 로 비슷비슷하다는 느낌입니다.
URPM
- 모델페이지 : https://civitai.com/models/2661/uber-realistic-porn-merge-urpm
- 다운로드 링크 : https://civitai.com/api/download/models/15640
 |
 |
 |
URPM은 이름에서 보는 것처럼 포*노 스타일의 사진이 많이 학습된 듯 하지만, 그냥 평범한 인물 사진도 잘 나오네요. 특히 해부학적으로 잘못된 사진이 거의 안나오고, Realistic Vision v2.0보다 좀 더 세련된 듯하다고 합니다.
비교
사실적인 (여성) 인물 사진이라는 관점에서 볼 때, 맨처음의 Stable Diffusion 1.5 기본 모델과 동양인들이 모델인 ChilloutMixf를 제외하면, 나머지는 거의 비슷한 듯 싶습니다. 그래도 선택해야 한다면 저도 Realistic Vision v2.0 과 URPM이 어떨까 싶네요.
LoRA, hypernetwork, textual inversion
로라, 하이퍼네트워크, 텍스트 인버전 등의 모델 수정자를 입력하여, 좀더 모델을 세밀하게 다룰 수 있습니다. 이러한 모델 수정자를 확보할 수 있는 가장 좋은 곳은 civitai.com 입니다.
한국 미인
ChilloutMix와 Ulzzang-6500 임베딩(embedding)을 사용하면 한국 아이돌 얼굴을 연출할 수 있습니다.

어두운 이미지
epi_noiseoffset을 사용하면 Stable Diffusion에서 일반적으로 얻을 수 있는 이미지보다 더 어두운 이미지를 생성할 수 있습니다. 이때 "dark studio", "night", "dimly lit" 등의 키워드를 사용해야 합니다.
프롬프트 : night, (dark studio:1.3) photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores <lora:epiNoiseoffset_v2:1>
부정적 프롬프트 : disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
아래는 프롬프트를 URPM 모델에 적용한 결과입니다. 보시는 것처럼, 배경이 어두워진 건 좋은데, 16장 생성한 중에서 검은색 옷이 아닌 이미지가 하나도 없네요. ㅠㅠ
 |
 |
 |
유명인 LoRA
자신이 좋아하는 아티스트에게 헌정한, 팬들이 작성한 LoRA 모델이 아주 많습니다. 물론 우리나라 배우들 LoRA도 많고요. https://civitai.com/?query=lora 으로 검색해보면 여러가지 LoRA들이 많이 나오는데 이중에서 찾아보시면 됩니다.
Natalie Portman「LoRa」
다운로드 링크 : https://civitai.com/api/download/models/11178

아이유
다운로드 링크 : https://civitai.com/api/download/models/18576

의복
Civitai.com에는 중국식 한복(hanfu) LoRA가 올라와 있는데, 여기를 누르면 정말 한국식 한복 LoRA를 만날 수 있습니다. 아래는 한복 LoRA와 Ulzzang-6500 임베딩을 함께 이용했습니다. 물론 모델은 ChilloutMix입니다.
프롬프트 : photo of young woman, highlight hair, outside, rural landscape, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores <lora:Hanbok_LoRA_V2:1>, korean clothes, hanbok, ulzzang-6500-v1.1
 |
 |
 |
 |
자세 제어
콘트롤 넷(Control Net)
콘트롤 넷은 사람의 자세를 제어하고 이미지의 구도를 제어하기 위한 사실상의 표준으로 자리잡고 있습니다. 그런데 콘트롤 넷을 사용하기 위해서는 참조할 수 있는 이미지가 필요합니다. 이런 이미지를 찾으려면, Unsplash와 같은 사진 사이트에서 man, woman, stand, sit 등 원하는 키워드를 입력해서 검색하면 됩니다.
콘트롤넷은 자신이 원하는 이미지를 생성하는데 필수적인 기능입니다. 자세한 사항은 ControlNet사용법(1) 과 ControlNet 사용법 (2)를 참고하세요.
민, 푸른하늘
이 글은 Andrew님의 글(https://stable-diffusion-art.com/realistic-people/)을 보면서 제 나름대로 돌리고, 필요하면 수정하면서 작성한 글입니다.
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기
- Stable Diffusion - 인페인트 가이드
- Stable Diffusion - 모델에 대한 모든 것
- Stable Diffusion - LoRA 모델 사용법
- Stable Diffusion - ControlNet 사용법(1)
- Stable Diffusion - ControlNet 사용법(2)
- Stable Diffusion - 하이퍼네트워크 사용법
- Stable Diffusion - AI 확대도구 사용법
- Stable Diffusion - 구역분할 프롬프트 사용법
- Stable Diffusion으로 멋진 이미지 만들기