스테이블 디퓨전을 사용하는 분들중 대부분은 AUTOMATIC1111 웹UI를 사용합니다. 그만큼 대중적이기도 하고 사용하기 쉽기 때문입니다. 하지만, 사용할 수 있는 방식이 정해져 있다보니 어떤 절차를 거쳐 이미지가 생성하는지 알기도 힘들고, 이 절차를 마음대로 수정하기도 쉽지 않습니다. ComfyUI는 이러한 AUTOMATIC1111의 단점을 극복할 수 있는 웹UI입니다. Stable Diffusion 모델의 워크플로를 좀 더 자세히 알 수 있고 세밀하게 조정할 수 있습니다. 대신 사용하기가 쉽지는 않죠.
이 글에서는 이전 글에 이어 빈 ComfyUI 캔버스로부터 시작해서 SDXL 모델을 사용해서 이미지를 생성하기 까지 한 단계씩 워크플로를 만들어가는 과정을 설명합니다.
이 글은 아래와 같이 구성되어 있습니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(1) - 기초 - 이 글. 아주 간단한 기본 SDXL 워크플로를 생성합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(2) - 조건부여 - SDXL 에만 적용되는 조건부터를 추가하고, 조건부여 파라미터 변경에 따른 이미지 영향을 시험합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(3) - Refiner - 완전한 SDXL 프로세스를 위해 refiner 모델을 추가합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(4) - LoRA - 커스텀 노드를 설치하고 LoRA를 사용하는 워크플로를 생성합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(5) - img2img - img2img 를 사용하는 워크플로를 생성합니다.
SDXL에서의 조건부여(Conditioning)
SDXL 논문에 따르면, SDXL은 이전 버전의 스테이블 디퓨전(1.4/1.5/2.0/2.1)에 비해 몇가지 중대한 변화가 일어났습니다. 이러한 변화중 세 가지는 이른바 조건부여 범주에 속합니다. 좀 더 단순화하자면, 기존에는 프롬프트와 이미지 만으로 모델을 학습시켰다면, SDXL에서는 데이터 세트에 대한 정보, 이미지 정보(크기 등)도 포함하여 학습되었습니다.
이제 추론 프로세스(이미지 생성 프로세스)중에 모델이 학습되었으므로, 이러한 추가 조건부여 매개변수를 전달할 수 있게 되었고, 이는 출력 이미지에 매우 큰 영향을 미칠 수 있어, 엄청난 의미를 가질 수 있습니다. 즉, 이러한 매개변수 값을 추가하면 모델이 원본 이미지 데이터 세트중 일부 하위집합만을 특정하게 되며, 따라서 이들 매개변수 값에 따라 프롬프트가 잘 작동할 수도 있고 아닐 수도 있다는 것입니다. 물론 이러한 조합이 드러나 있지 않기 때문에 최적의 조합을 찾기위해서는 원본 데이터에 대한 면밀한 검토와 함께 추가적인 실험이 필요할 수 있어 매우 어려울 것으로 예상됩니다.
아래는 조건부여 범주에 속한 변화 세가지를 간략하게 설명한 것입니다.
- 이미지 크기: 이전 SD에서는 512x512 이하의 이미지는 사용하지 않았으나(논문에 따르면 39%에 달한다고 합니다), SDXL에서는 이러한 저해상도 이미지도 사용합니다. 그 대신 이미지 크기도 모델 학습에 사용하였습니다.
- 크롭 매개변수: 이전 SD에서는 512x512 크기로만 이미지를 학습하였기 때문에 종횡비가 다른 이미지(정사각형이 아닌 이미지)는 긴 쪽을 잘라내고 학습하였습니다. 이 과정에서 일부 중요한 이미지(예를 들면 얼굴 윗부분)가 잘려나갈 수 있었습니다. SDXL 에서는 이를 처리하기 위하여 학습과정에서 크롭(자르기) 매개변수 값을 모델에 입력하였으며, 논문에서 언급한 것처럼 추론시 크롭을 (0,0)으로 설정하면 자르기로 인해 발생하는 문제가 대부분 해결됩니다.
- 종횡비(Aspect Ratio) 그룹 : SDXL 은 다양한 종횡비 이미지에 대해 미세조정하였습니다. 다만, 모든 종횡비를 다 사용하는 것이 아니라, 1:1, 4:3, 16:9 등 특정한 종횡비 그룹으로 묶어서 학습시키고, 이 값을 모델에 입력하였습니다. 따라서 이론적으로는 종횡비를 다르게 입력하면 생성되는 이미지가 다르게 나오게 됩니다. 또한 학습에 사용된 종횡비를 사용하여야 좋은 결과를 얻을 수 있습니다. 하지만, 이 조합을 따르지 않으면 흥미로운 결과가 생길 가능성도 있습니다.
이러한 맥락을 고려하여 이들 매개변수를 ComfyUI 워크플로에 추가시켜보겠습니다.
크기(Size) 및 자르기(Crop) 조건부여 구현
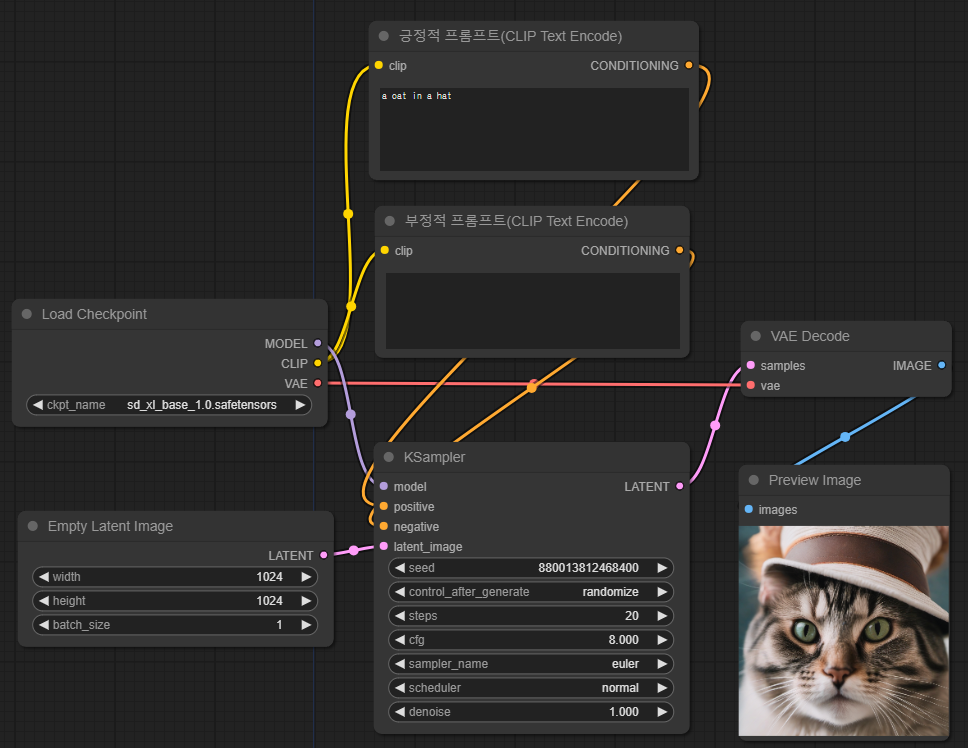
우리는 이전 글에서 최종적으로 생성한 워크플로로부터 시작합니다. 이 워크플로는 아래와 같습니다.

처음부터 이 워크플로를 만들지 않고 그냥 불러서 쓰고 싶다면 아래의 이미지를 다운로드 받아서 빈 캔버스에 드래그해 떨어뜨리면 됩니다(혹은 메뉴에서 [Load] 버튼을 눌러 아래 이미지를 불러오면 됩니다). 이처럼 ComfyUI로 생성한 이미지에는 해당 이미지를 생성할 때 사용한 워크플로가 그대로 포함되어 있습니다.

이제 이 워크플로에 SDXL 이미지 값(출력 이미지 크기가 아닌 이미지를 생성하는데 사용되는 입력 값)과 이미지 크롭 크기값을 입력할 방법이 필요합니다. ComfyUI에서는 간단히 처리할 수 있습니다. 긍정적 프롬프트와 부정적 프롬프트 노드를 없애고, 새로운 SDXL용 프롬프트 노드로 대체하면 됩니다.
이를 위해서 아래 그림과 같이 빈 캔버스를 우클릭하고 Add Node -> advanced -> conditioning -> CLIPTextEncodeSDXL 을 선택합니다.
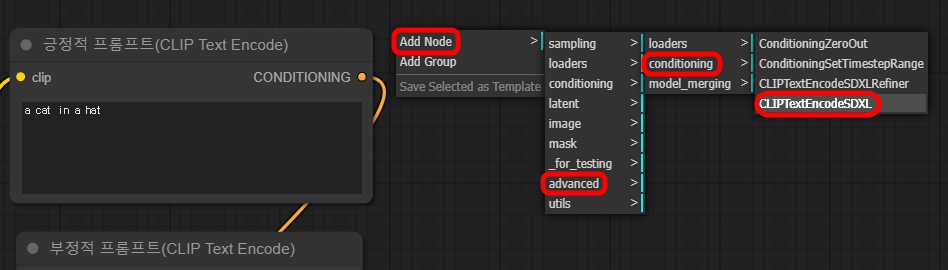
추가된 SDXL용 CLIP 텍스트 인코더는 아래와 같습니다.
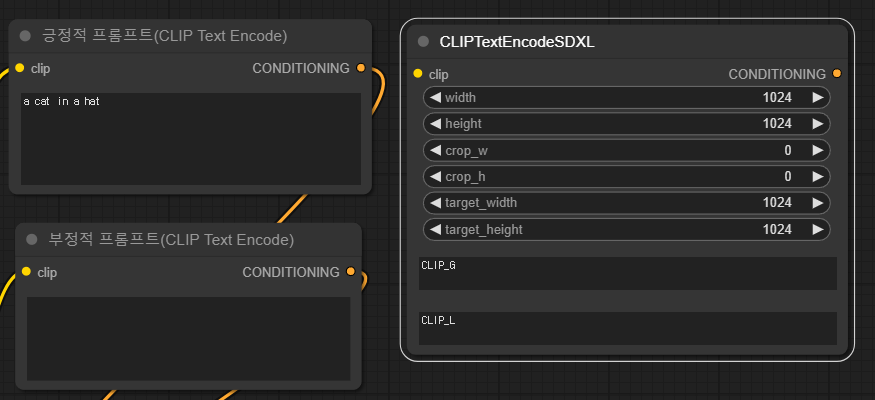
- 예전의 텍스트 인코더 노드와 마찬가지로, CLIPTextEncodeSDXL 노드도 왼쪽에 입력 슬롯 하나(clip), 오른쪽에 출력 슬롯 CONDITIONING 이 존재합니다. 따라서 clip은 체크포인트 노드에 연결해주고, CONDITIONING은 KSampler 노드에 연결해 주어야 합니다.
- 입력 매개변수 6개가 추가되었습니다. 이미지 폭(width)와 높이(height) (단, 이는 출력 이미지 크기와는 관계 없으며, 조건부여로만 사용됩니다.) 크롭 폭과 높이(크롭 조건부여), 마지막으로 목표 이미지 폭과 높이(종횡비 그룹의 이미지 크기) 등
- 마지막으로 CLIP_G와 CLIP_L 텍스트 입력 항이 추가되었습니다. G와 L은 SDXL이 사용하는 두가지 텍스트 인코더인 OpenCLIPViT-bigG와, CLIPViT-L을 각각 나타냅니다. 이상하게도 두개의 텍스트를 따로 입력할 수 있지만, 두개를 동일하게 입력하는 것이 나을 것 같습니다. 이에 대해서는 아래에서 테스트해보겠습니다.
이제 SDXL용 텍스트 인코더를 워크플로에 추가시켜보겠습니다. 순서는 아래와 같습니다.
- CLIPTextEncodeSDXL 노드를 하나 더 추가합니다(빈 캔버스에서 우클릭하여 Add Node -> advanced -> conditioning -> CLIPTextEncodeSDXL)
- 하나는 긍정적 프롬프트(Positive Prompt), 다른 하나는 부정적 프롬프트로 제목을 바꿔줍니다. 해당 노드를 우클릭한뒤, TiTLE을 클릭하면 수정할 수 있습니다.
- 이전의 프롬프트는 두개 모두 삭제합니다(클릭한 상태에서 Del 키를 누르면 됩니다).
- 이제 슬롯을 연결합니다. CLIPTextEncodeSDXL 노드의 좌측 입력 clip 슬롯과 체크포인트 노드의 우측 출력 CLIP 슬롯과 연결해주고, 우측의 CONDITIONING은 각각 positive와 negative 슬롯에 연결시켜주면 됩니다(슬롯옆의 점을 좌클릭-드래그해서 목표점에서 떨어뜨리면 됩니다).
아래가 결과입니다. 형태는 다를 수 있지만, 연결은 아래와 동일해야 합니다.

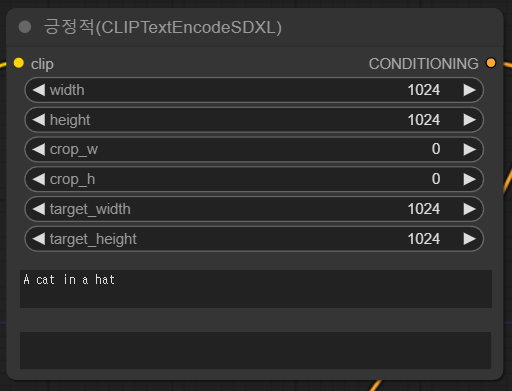
이제 테스트해볼 시간입니다. 긍정적 프롬프트의 CLIP_G, CLIP_L 모두에 "A cat in a hat"을 입력하고, 부정적 프롬프트는 그대로 비워둔 상태로 우측 메뉴의 [Queue Prompt] 버튼을 클릭하면 잠시후 아래와 같은 이미지가 생성됩니다.

이미지는 약간 달라지긴 했지만, 기본적으로 새로 추가한 조건부여가 생성된 이미지에 그다지 영향을 미치지 않았습니다.
CLIP_G와 CLIP_L 프롬프트 입력 시험
SDXL 논문에 따르면 SDXL은 두가지 텍스트 인코더를 사용하고 있습니다.
구체적으로, CLIP ViT-L 과 함께 OpenCLIP ViT-bigG를 사용하여, 두 번째 텍스트 인코더 출력을 채널 축을 따라 연결합니다.
간단히 설명하자면, 프롬프트를 입력하면 CLIP_G와 CLIP_L 등 두개의 모델이 각각 입력된 텍스틀를 특정한 형식의 숫자로 변환합니다. 그 다음 이들 숫자들 합한 다음(연결), 이것을 UNET에 전달합니다.
위에서 본 것처럼, ComfyUI는 두개의 모델에 각각 별도로 텍스트를 입력할 수 있습니다(적어도 인터페이스 상으로는 그렇습니다. 프로그램이 어떻게 작동하는지는 확실치 않지만요). 그래서 직접 테스트해보겠습니다.
CLIP_G만 입력했을 경우
아래처럼 입력한 경우입니다.
아래는 첫 시드번호(567377663058251)를 기준으로 4장을 뽑아본 결과입니다. 확실히 달라졌습니다. 씨드번호가 동일한데도 말이죠. 즉, 프롬프트를 다르게 인식했다는 뜻입니다. 이미지 품질은... 원본 글에서는 떨어졌다고 하는데 저는 잘 모르겠네요.
 |
 |
 |
 |
이번엔 아래위에 약간 다른 프롬프트를 넣어보겠습니다. 시드번호는 동일합니다.
CLIP_G 프롬프트: a cat in a hat
CLIP_L 프롬프트: a dog in a hat
모자 쓴 고양이도 나오고 모자쓴 강아지도 나오네요. 그런데, 강아지를 잘 살펴보면 고양이의 특징이 조금 들어 있습니다. 확실히 CLIP_G 의 영향이 좀 더 큰 것 같습니다.
 |
 |
 |
 |
이번엔 두개의 프롬프트를 완전히 다르게 입력해 보겠습니다.
CLIP_G: an astronaut riding a pig
CLIP_L: Panda mad scientist mixing sparkling chemicals, artstation
 |
 |
 |
 |
이렇게 섞으니 재미있는 결과가 나오네요. 흥미롭습니다. 대체적으로 보면 CLIP_G의 영향이 큰 것 같습니다. 대부분 우주인의 모습을 하고 있으니까요. 판다 이미지가 군데군데 섞여 있기는 하지만요.
이렇게 CLIP_G와 CLIP_L이 각각 어떻게 영향을 주는 지 알았지만, 대부분의 경우 두가지 입력을 다르게 설정해야 할 필요가 없습니다. 즉, CLIPTextEncodeSDXL을 사용하려면 프롬프트를 복붙해야 한다는 거죠. 이것을 막고, 긍정적/부정적 프롬프트를 각각 한번만 입력하도록 워크플로를 바꿔보겠습니다.
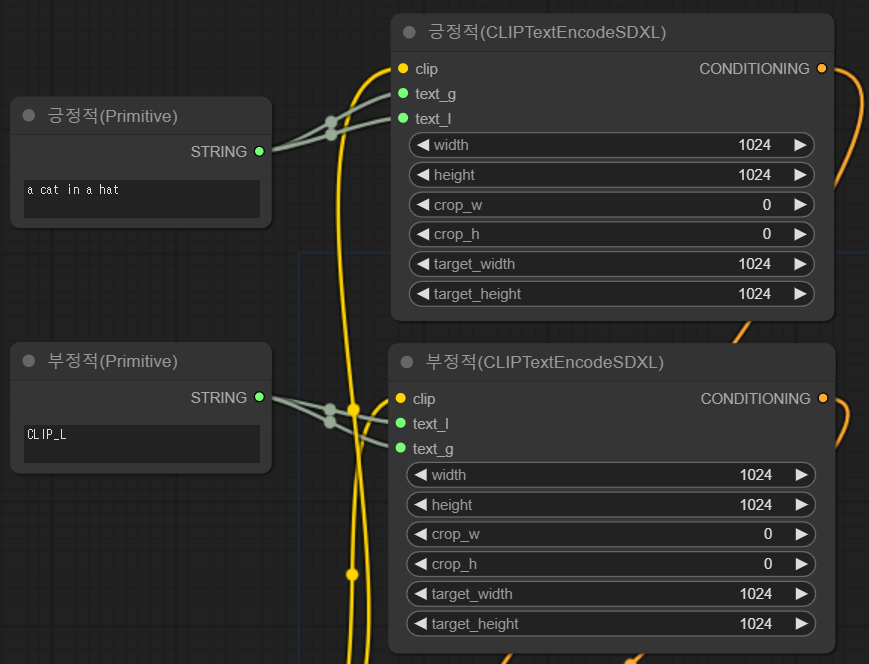
먼저 긍정적(CLIPTextEncodeSDXL) 노드를 우클릭하고, Convert text_g to input, Convert text_l to input을 선택합니다(두번 해야 합니다.)

그러면 아래와 같이 아래쪽의 CLIP_G/CLIP_L 입력란은 사라지고 노드 좌측에 text_g/text_l 입력 슬롯이 생깁니다.
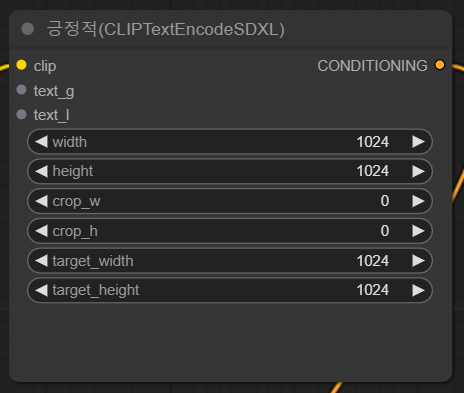
이제 그냥 텍스트만 입력하는 노드를 추가해줍니다. Add Node -> utils -> Primitive 를 선택해주면 됩니다.
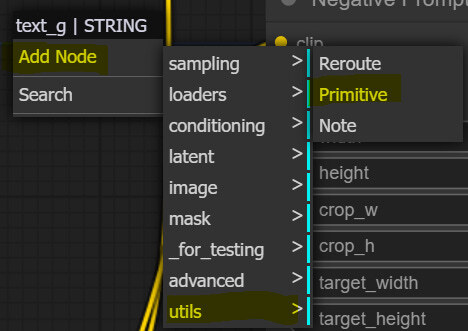
그러면 아래와 같은 노드가 추가됩니다.

이제 우측에 있는 출력 슬롯을 CLIPTextEncodeSDXL 노드의 text_g/text_l 입력 슬롯에 연결해주고 Title을 수정해줍니다. 긍정적 부정적 프롬프트 모두에 대해 동일하게 작업해주면 아래와 같은 결과가 됩니다. 이제 왼쪽에 있는 Primitive 노드에 입력하면 CLIP_G, CLIP_L에 동일한 프롬프트를 넣는 것과 동일해 집니다.
이미지 크기 조건부여 실험
우리의 가정에 따르면 학습 데이터 세트가 균등하게 분포하지 않는다는 것입니다. 예를 들어 픽셀 아트는 대부분 128x128 해상도에 존재하고, 초상화 스타일은 512x512에, 디지털 일러스트레이션은 1024x1024 해상도에 더 많이 분포되었다는 가정입니다. 따라서, 적절하게 조건부여를 하면 특정 학습 데이터셋을 참조할 수 있으므로, 생성하려는 이미지 종류에 따라 해상도/종횡비에 따른 조건을 달리 부여하는 것이 필요한가를 알고 싶은 것입니다. 이것을 시험해 보겠습니다.
우선 SDXL 논문에서 했던 것을 그대로 따라해보겠습니다. 먼저 표준적인 매개변수를 사용해서 비교용 이미지를 생성합니다. 논문 저자들은 512x512 모델에 사용하였는데, 시드번호는 알 수 없어서 정확한 비교는 힘듧니다. 일단 아래와 같이 설정해서 출력한 결과입니다.
| 프롬프트: A robot painted as graffiti on a brick wall. a sidewalk is in front of the wall, and the grass is growing out of cracks in the concrete.” 시드번호: 11 잠재 이미지 크기: 1024x1024 이미지크기 조건부여: 변경(우측그림 참조) 샘플링 알고리즘: ddim CFG: 8 스텝수: 50 |
 |
아래는 이미지크기 조건부여만 (64x64, 128x128, 256x236, 512x512, 1024x1024, 2048x2048)로 바꿔가면서 생성한 결과입니다.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
왼쪽 사진의 머리부분만 확대시켜보겠습니다.
 |
 |
 |
 |
 |
 |
일단 64x64 이미지와 128x128 이미지는 확실히 흐릿하다는 걸 알 수 있습니다. 최종 이미지가 1024x1024인데도 조건부여쪽 이미지 크기를 줄이면 흐린 이미지가 나오는 건 확실합니다. 그런데 그 이상의 크기에서는 약간씩 다르긴 한데 별 차이는 안보이는 것 같습니다. 특히 맨 마지막 2048x2048의 경우 배경이 좀더 선명하게 보이고 디테일도 살아난 듯 싶지만, 항상 이런지는 확신이 서지 않습니다.
원본 글에서는 실사 이미지에 대해서 이미지크기 조건부여를 64x64, 256x256, 512x512, 1024x1024로 바꿔가며 실험했는데, 그다지 명쾌한 차이가 보이지는 않는 듯 싶습니다.
 |
 |
 |
 |
크롭 매개변수에 따른 실험
원본 글에서는 크롭 조건부여에 대해 (0,0)과 (512,0) 두고 비교했는데, 그다지눈에 띄는 변화가 없다고 하네요. 그냥 0,0 기본 값을 사용하는 것이 좋겠다고 합니다.
종횡비 조건부여에 따른 실험
종횡비에 대해선 일단, 최종 이미지의 종횡비가 조건부여의 종횡비와 비슷할 때 품질이 좋은 이미지가 생성될 것이라고 가정해 보겠습니다.
일단 실험을 해보겠습니다. 인물사진은 세로로 찍은 사진이 많습니다. 그래서 사실적인 인물사진 생성방법에서 사용했던 프롬프트를 사용하되, 다음과 같은 설정으로 실험하였습니다.
프롬프트: photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K, UHD, highly detailed glossy eyes, high detailed skin, skin pores
최종 이미지 크기: 768x1024
이미지 크기 조건부여: 1024x1024 (변경없음)
종횡비 조건부여: 1:2, 2:3, 1:1, 3:2, 2:1, 3:1
샘플링 알고리즘: euler
CFG: 8
스텝수: 30
 |
 |
 |
 |
 |
 |
뭐... 거의 차이가 없습니다. 물론 확실히 영향이 없다고는 결론 짓기 힘듧니다. 완벽하게 테스트해보려면, 최종이미지/이미지 크기/크롭/종횡비 에 대해 조건을 바꿔가며 모두 실험해 봐야 하는데, 각각 5가지라고만 잡아도 5x5x5x5 가지를 실험해 봐야 합니다. 만약 부정적 프롬프트에 대해서도 실험한다면 훨씬 더 복잡할테구요. 그리고 그 결과에 대해 눈으로 평가하는 게 아니라, 어떤 정량적인 평가가 있어야겠죠. 물론 저는 불가능합니다.
어쨌든 맨처음에 이미지 크기 조건부여를 64 혹은 128로 두면 확실히 이미지 품질이 떨어진다는 것만 제외하면 다른 조건부여(conditioning)은 그다지 영향이 없다고 잠정적으로 결론을 내려도 될 것 같네요.
최종 워크플로 최적화
이 상태라면 워크플로를 수정할 필요는 없을 것 같습니다. 이미지크기나 종횡비가 그다지 영향이 없다면 이러한 조건부여들은 그냥 무시해버리면되고, 따라서 CLIPTextEncodeSDXL 을 사용할 의미는 별로 보이지 않습니다. 그렇다면 프롬프트만 입력하면되고, 따라서 맨 처음에 있는 워크플로만으로도 충분해 보입니다.
그런데 원본 글에서는 이미지 크기, 크롭 및 종횡비 조건부여에 대해서도 모두 별도의 노드로 분리하는 방법으로 새로운 워크플로를 만들었습니다. 다음 글에서 필요하답니다. 아래처럼요. 만드는 방법은 먼저 (CLIPTextEncodeSDXL) 노드를 우클릭하고, 6개의 조건부여에 대해 Convert xxxx to input 을 눌러 입력 슬롯으로 바꾸고, 각각에 대해 Add Node -> utils -> Primitive를 눌러 노드를 추가한 후 입력 슬롯에 연결해주면 됩니다. 구분하기 위해서 제목(Tiltle)도 수정해야겠네요.
그림이 많이 복잡해보이긴 하지만, 하나하나 뜯어보면 그다지 이해하기 어렵지는 않을 겁니다.
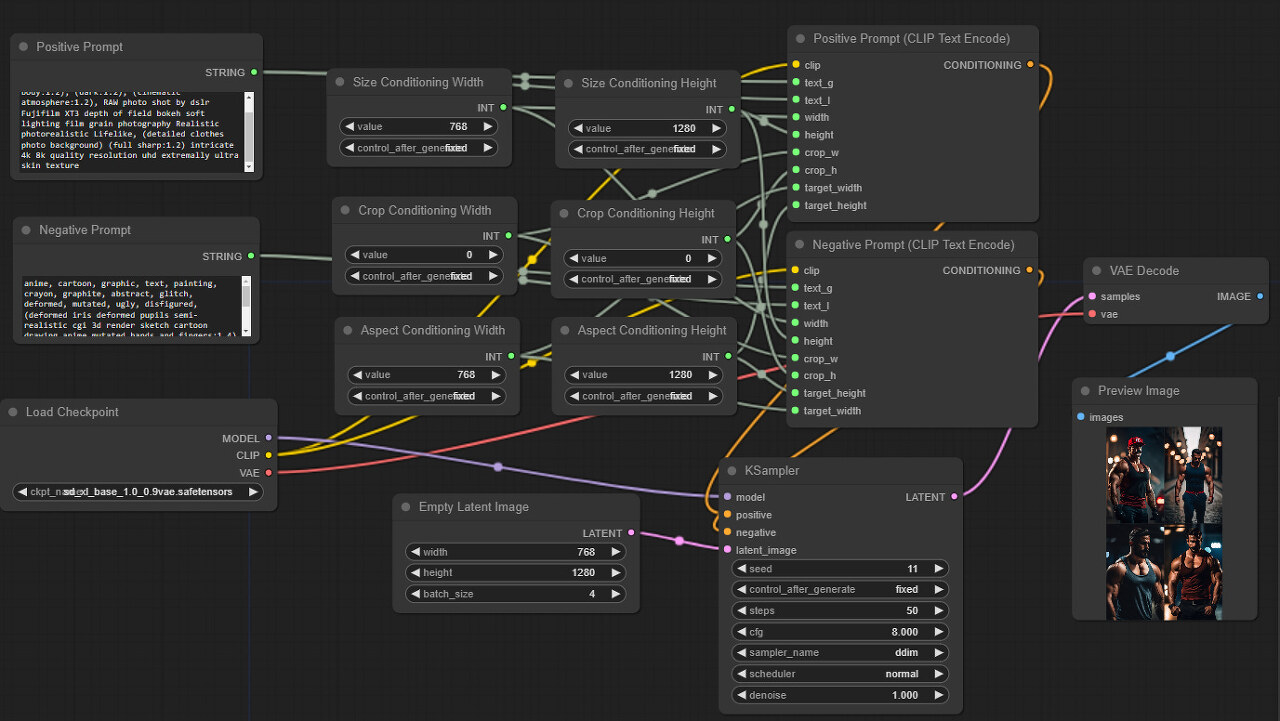
어쨌든 이러한 워크플로가 다음 글에서 필요하다고 하니 새로 만들어야 하지만, 그냥 아래에 있는 그림을 저장한 후 캔버스에 떨어뜨리면 위의 워크플로를 그대로 사용할 수 있습니다.

이상입니다. 사실 저도 SDXL 논문을 읽고나서 크기나 종횡비에 대한 조건부여가 이미지 품질에 어떤 영향을 미칠지 궁금했었는데, 이렇게 직접 실험을 해서 결론을 도출하니 기분이 좋습니다. 그다지 영향이 많지 않다는 것은 약간 실망스럽긴 하지만요. ㅎㅎ
민, 푸른하늘
이 글은 https://followfoxai.substack.com/p/part-2-sdxl-in-comfyui-from-scratch 를 번역하면서 필요에 따라 수정 편집하여 작성한 글입니다.
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 초보자 가이드
- ComfyUI를 위한 유용한 정보
- ComfyUI 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기