스테이블 디퓨전을 사용하는 분들중 대부분은 AUTOMATIC1111 웹UI를 사용합니다. 그만큼 대중적이기도 하고 사용하기 쉽기 때문입니다. 하지만, 사용할 수 있는 방식이 정해져 있다보니 어떤 절차를 거쳐 이미지가 생성하는지 알기도 힘들고, 이 절차를 마음대로 수정하기도 쉽지 않습니다. ComfyUI는 이러한 AUTOMATIC1111의 단점을 극복할 수 있는 웹UI입니다. Stable Diffusion 모델의 워크플로를 좀 더 자세히 알 수 있고 세밀하게 조정할 수 있습니다. 대신 사용하기가 쉽지는 않죠.
이 글에서는 빈 ComfyUI 캔버스로부터 시작해서 SDXL 모델을 사용해서 이미지를 생성하기 까지 한 단계씩 워크플로를 만들어가는 과정을 설명합니다. 이를 통해 스테이블 디퓨전, ComfyUI 도구 및 SDXL 파이프라인이 작동되는 방식에 대한 기본적인 사항을 알 수 있습니다. 이 글은 아래와 같이 구성됩니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(1) - 기초 - 이 글. 아주 간단한 기본 SDXL 워크플로를 생성합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(2) - 조건부여 - SDXL 에만 적용되는 조건부터를 추가하고, 조건부여 파라미터 변경에 따른 이미지 영향을 시험합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(3) - Refiner - 완전한 SDXL 프로세스를 위해 refiner 모델을 추가합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(4) - LoRA - 커스텀 노드를 설치하고 LoRA를 사용하는 워크플로를 생성합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(5) - img2img - img2img 를 사용하는 워크플로를 생성합니다.
SDXL이 공개되면서, ComfyUI의 인기가 상승하고 있는 것 같습니다. 특히 SDXL 워크플로가 정리되지 않은 당분간은 보다 잘 통제할 수 있고, 섬세하게 조정할 수 있어, 점점 인기가 높아질 것으로 예상합니다. 아직까지는 복잡한 미세조정(Fine tuned) 모델도 거의 없고, 모범적인 사례도 거의 없는 상태로서, 이 도구를 사용하면 단기적으로 새로운 모범 사례를 생성하는 데 매우 도움이 될 것으로 예상됩니다. 장기적으로는 모범 사례가 등장하면서 더 간단한 워크플로가 나올 수도 있습니다. 그러면 ComfyUI의 인기도 조금 식을 수도 있겠죠. 하지만, 전문성을 갖춘 열정적인 분들은 이 복잡한 도구를 계속 사용할 것으로 생각합니다.
개요
ComfyUI(링크)는 스테이블 디퓨전을 위한, 그래프/노드/플로차트 기반의 인터페이스입니다. ComfyUI를 설치하는 방법과 기본적인 사용방법은 ComfyUI 설치 및 사용법 기초를 참고하시기 바랍니다.
스테이블 디퓨전은 간단히 말해 Text to Image 모델, 즉 텍스트를 입력하면 이미지를 생성해주는 모델이지만, 내부적으로는 매우 복잡한 프로세스로 구성되어 있습니다. 즉, 입력(텍스트)와 출력(이미지)사이에는, 보이지도 않고 일반적으로는 관심도 두지 않지만, 많은 단계가 존재합니다. 기본적으로 SD 모델은 적어도 세가지 부분으로 구성됩니다.
- 텍스트 인코더(Text Encoder): 텍스트 인코더는 사용자가 입력한 텍스트를 모델이 이해할 수 있는 특정한 숫자들의 조합으로 변환합니다. 스테이블 디퓨전에서 사용하는 텍스트 인코더는 CLIP 모델입니다. 따라서 텍스트 인코더라는 말대신 CLIP 이란 단어로 대체하기도 합니다.
- UNET: 모델의 가장 중요한 부분으로서 (어떤 특정 숫자 및 텍스트 인코더에서 나온 숫자로 이루어진) 잡음에서 출발하여 (이미지로 바꿀 수 있는) 또 다른 숫자 조합으로 만들어주는 부분입니다.
- VAE: UNET에서 나온 숫자 조합을 이미지로 바꿔주는 모델입니다. 반대로 이미지를 숫자 조합으로 바꾸는 것도 가능합니다.
이들 각각의 부분은 서로 연결되어 통신합니다. 이와 동시에 각 단계를 제어할 수 있는 매우 많은 매개변수 목록을 통해 모델이 어떻게 작동할 지를 지시할 수 있습니다. 이 과정만으로도 상당히 복잡하다고 할 수 있는데, 스테이블 디퓨전 사용자들은 이러한 프로세스의 앞/뒤로 새로운 워크플로를 추가해 높은 품질의 이미지를 생성하고 있습니다. 간단한 예가 AI 확대기(Upscaler)로서, 별도의 확대용 모듈을 불러들이고 여기에 파라미터를 추가한 뒤, 이를 이미지 생성 프로세스에 통합하는 방식으로 작동됩니다.
스테이블 디퓨전에 대한 기본적인 이론에 관심있으신 분은 이 글을 읽어보시기 바랍니다.
한가지 더 언급하고 싶은 것은, SDXL의 경우는 이 모든 과정을 하나의 모델이 아니라 두개의 모델 아키텍처를 도입함으로써 품질을 더 높이는 방법을 채택했다는 것입니다. 이로 인해 통신 및 매개변수 숫자가 두 배로 증가하게 되었습니다.
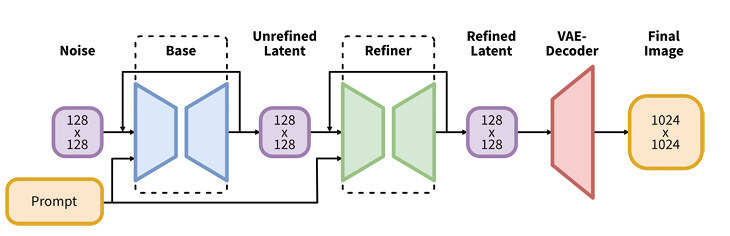
ComfyUI를 한번이라도 사용해보신 분이라면, 관련 논문 에 포함된 그림(위 그림)이 ComfyUI와 유사하다는 것을 아실 것입니다. 즉, 이미지 생성 프로세스의 각 부분이 선으로 연결되어 있습니다. 이것이 바로 ComfyUI가 하는 일입니다. 즉 이미지 생성에 관련된 각 부분을 구획(노드)으로 나누고, 이들 각 부분을 제어할 수 있는 레버와 구획간의 연결(선/링크)을 시각적으로 제공하는 것입니다.
Base SDXL 기반 이미지 생성 프로세스
먼저 미리 제공되는 워크플로를 사용하여 이미지를 생성해 보겠습니다.
첫번째 목표는 아무것도 없는 곳에서 시작해서 SDXL 모델로 이미지를 생성하는 간단한 워크플로를 구축하는 것입니다. 여기에서는 가장 간단하게 구성하며, 필요에 따라 이 워크플로를 확장해 갈 수 있습니다.
스테이블 디퓨전이 어떻게 작동하는지를 이해하셨다면, 다음과 같은 것들이 필요함을 아실 수 있습니다.
- 텍스트 프롬프트를 입력할 수 있는 노드
- 위의 세부분이 모두 포함된 체크포인트 모델을 불러들일 노드
- 텍스트 프롬프트를 인코딩하는 노드
- UNET 을 구동하는 샘플러(Sampler) 노드
- UNET에서 생성된 숫자를 이미지로 변환해주는 디코더 노드
- 이미지를 표시해주는 공간 노드
ComfyUI 시작하기
먼저 comfyUI\ComfyUI_windows_portable\update 폴더에 들어가서 update_comfiui.bat을 실행시킵니다. 설치후 갱신된 내용을 업데이트 하는 것입니다. 그 다음 E:\comfyUI\ComfyUI_windows_portable 폴더에 있는 run_nvidia_gpu.bat를 실행시켜 주면 됩니다.
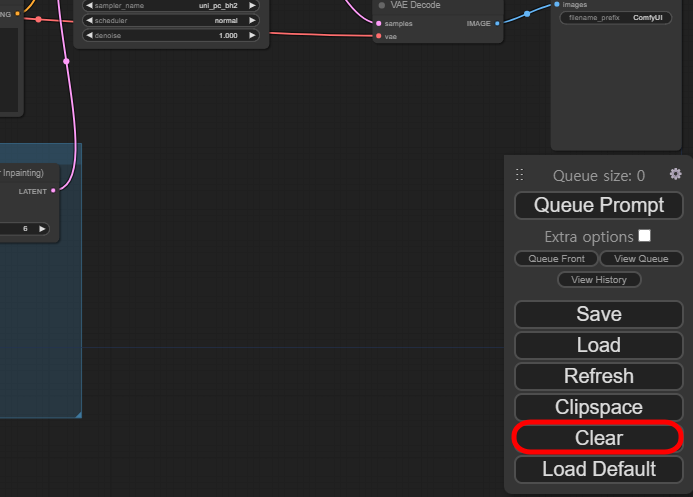
그러면 http://127.0.0.1:8188 주소로 웹브라우저가 자동 실행되고, 기본 워크플로가 나타나는데, 아래 그림과 같이 Clear를 누르면 이 워크플로가 지워지게 됩니다.
체크포인트 모델 불러오기
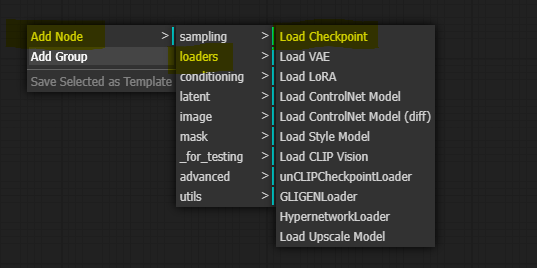
제일 먼저 해야 할 일은 모델을 불러오는 것입니다. 먼저 빈 화면 아무곳에서나 우클릭을하고 아래와 같이 Load Checkpoint (체크포인트 모델 불러오기)를 선택합니다.
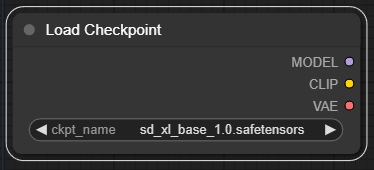
그러면 아래와 같이 모델을 선택하고 다른 노드와 연결할 수 있는 노드가 나타납니다. 여기에서sdXL_v10VAEFix.safetensors 모델을 선택합니다. 좌우 삼각형을 눌러도 되고, 이름 부분을 눌러서 직접 선택할 수도 있습니다.
체크포인트 파일이 없을 경우, 아래의 두가지 SDXL 파일을 다운로드 받아 ComfyUI_windows_portable\ComfyUI\models\checkpoints 속에 넣어주면 됩니다(AUTOMATIC1111에서 저장된 모델을 사용하고 싶을 경우, 여기를 읽어보세요)
- SDXL 1.0 base 모델 다운로드링크(sdXL_v10VAEFix.safetensors)
- SDXL 1.0 refiner 모델 다운로드링크(sdXL_v10RefinerVAEFix.safetensors)
위에서 스테이블 디퓨전 모델에서 가장 중요한 것이 텍스트 인코더(Text Encoder), UNET, VAE라고 설명했는데, 이것을 바로 위에있는 체크포인트 노드에서 확인할 수 있습니다. 즉, Model이 UNET에 해당하고, CLIP이 텍스트 인코더, VAE는 VAE에 대응됩니다. 이걸 보면 체크포인트 모델이 세가지 요소로 구성된다는 걸 좀 더 명확하게 알 수 있네요.
이렇게 노드가 나타나면, 여기저기를 눌러보면서 어떤 옵션이 있는지 확인해보는 것이 좋습니다. 또한 우클릭을 하면 아래와 같이 여러가지 파라미터를 선택할 수 있는 팝업메뉴가 나타납니다.
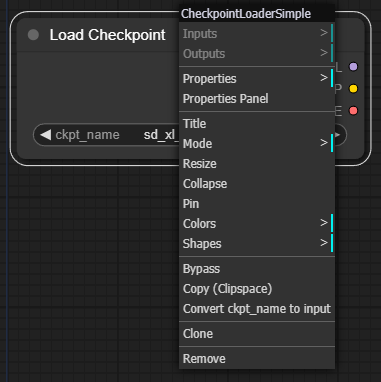
오른쪽에 있는 Model/CLIP/VAE 등은 출력 슬롯으로, 각각 SDXL base 모델에 포함된 세가지 부분을 나타냅니다.
샘플러(sampler) 추가
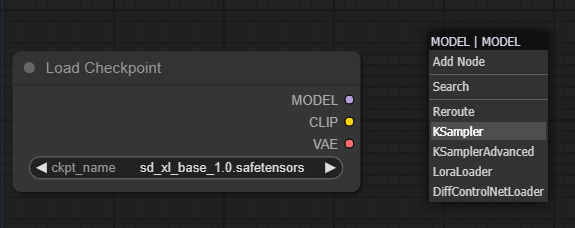
다음으로 출력 슬롯중 맨 위에 있는 연보라색 Model 슬롯에 연결하는 샘플러를 알아보겠습니다. 샘플러(샘플링 알고리즘)은 모든 것을 연결하고, 이미지 생성에 필요한 대부분의 것을 밀고 당기는 주요 엔진이라고 생각할 수 있습니다.
Model 출력 슬롯을 좌클릭-드래그하여 빈 캔버스 아무 곳에든 놓으면 아래와 같이 연결할 노드를 추가하는 옵션이 나타납니다. 고급 사용자라면 여기에서 [Add Node]를 눌러 좀더 복잡한 옵션을 선택할 수 있지만, 우리는 [KSampler] 노드를 선택합니다.
그러면 아래와 같이 [KSampler] 노드가 추가되고, 체크포인트 노드와 자동으로 연결됩니다.
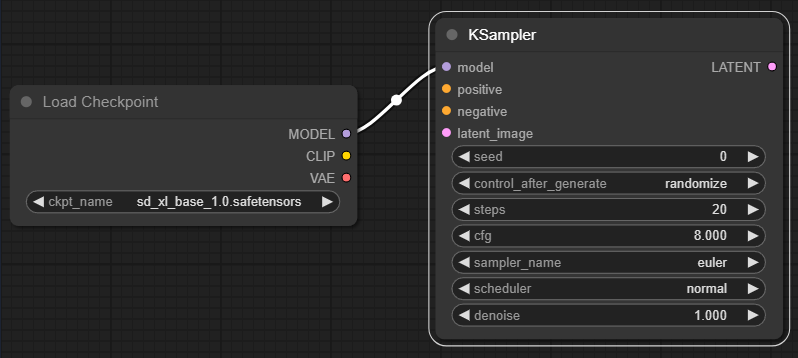
샘플링 알고리즘(위 그림에서 KSampler)는 체크포인트 파일에 포함된 모델을 사용해서 잡음을 잠재 이미지로 변환해 간다는 것을 알 수 있습니다. 이 과정에서 프롬프트와 잠재 이미지(Latent image)가 입력되어야 하는 것을 알 수 있네요.
KSampler 노드에는 좌측에 4개의 입력 슬롯이 있습니다.
- model : UNET을 불러오는 모델과 연결(이미 연결됨)
- positive/negative : 인코딩된 프롬프트와 부정적 프롬프트와 연결. 샘플러 노드에는 반드시 이 노드와 연결되어야 합니다.
- latent image : 위에서 설명한 것처럼, UNET은 잡음 이미지를 사용하여 이미지를 생성합니다. img2img의 경우에는 입력받은 이미지를 잡음 이미지로 사용합니다.
KSampler 노드 아래에는 6개의 매개변수가 있습니다.
- seed : 잡음 이미지를 생성하는 데 사용되는 씨드 번호를 입력합니다. 0이면 무작위로 선택됩니다.
- control_after_generate : 위의 씨드번호와 관계있습니다. 입력한 씨드번호를 고정하여(fixed) 사용할 수도, 증가시키거나 감소시킬 수도 있습니다. 기본 값은 무작위 선택(randomize)입니다.
- steps: 잡음 제거 단계 수 입니다. 기본값 20은 20회 수행한다는 뜻입니다.
- CFG: AUTOMATIC1111과 동일합니다. 높은 값을 입력하면 프롬프트에 있는 내용을 따르는 경향이 강해지고, 낮추면 프롬프트를 무시할 확률이 높아집니다.
- sampler_name, scheduler, denoise : 모두 이미지 생성을 제어하는 매개변수입니다.
마지막으로 오른쪽에는 분홍색 LATENT 출력 슬롯이 있습니다. 이 노드에서는 잠재 이미지(latent image)가 생성되는데, 이를 디코딩해 이미지로 만들어주는 VAE 노드와 연결해야 합니다.
프롬프트와 부정적 프롬프트, 텍스트 인코딩
이번엔 샘플러가 요구하는 프롬프트를 추가하도록 하겠습니다. 이번에도 마찬가지로 positive 바로앞의 주황색 단추를 드래그해서 아무곳이나 떨구면 아래와 같이 노드를 추가하는 화면이 나옵니다. 이 드룹다운에서 "CLIPTestEncoder"를 선택합니다. 부정적 프롬프트(negative)에 대해서도 동일하게 처리하면 됩니다. (부정적 프롬프트가 필요없다면 아얘 비워두셔도 됩니다.
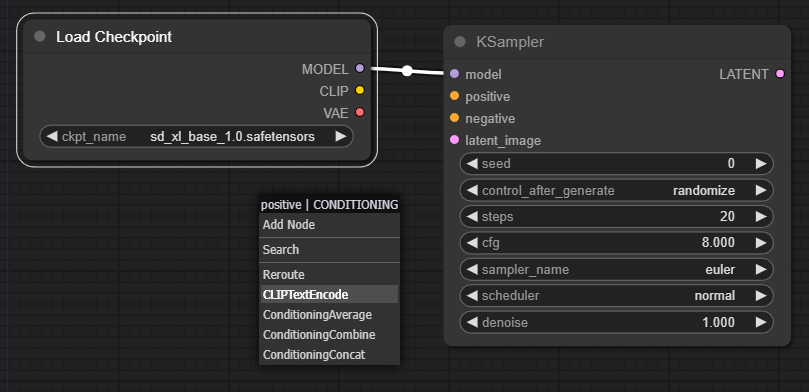
그 결과 아래와 같이 2개의 노드가 추가되었습니다. 이름이 동일해서 헛갈릴 수 있으니 이름을 수정해주었습니다(노드에서 우클릭을 하고 "Title"을 눌러주면 됩니다. 보시는 것처럼 한글도 입력가능합니다. 다만 나중에 확인해보니 한글이 깨지더군요 ㅠㅠ).
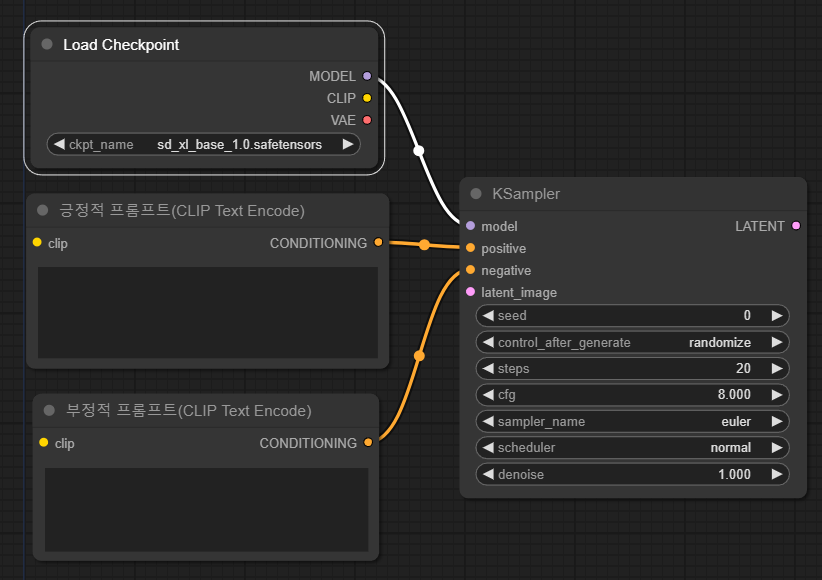
이제 텍스트 인코더 노드의 오른쪽 슬롯은 샘플러 노드와 연결되었습니다. 그런데, 왼쪽에는 아직 아무곳에도 연결되지 않은 노란색 clip 슬롯이 남아 있습니다. 이 슬롯은 CLIP 모델용이므로 체크포인트 모델 로더의 CLIP 슬롯에 연결합니다. 연결할 때에는 시작하는 슬롯에서 좌클릭-드래그하여 종착 슬롯에 떨어뜨려주면 됩니다. 결국 다음과 같은 결과물이 나올 것입니다: (프롬프트 내용은 아래에서 입력할 예정입니다.)
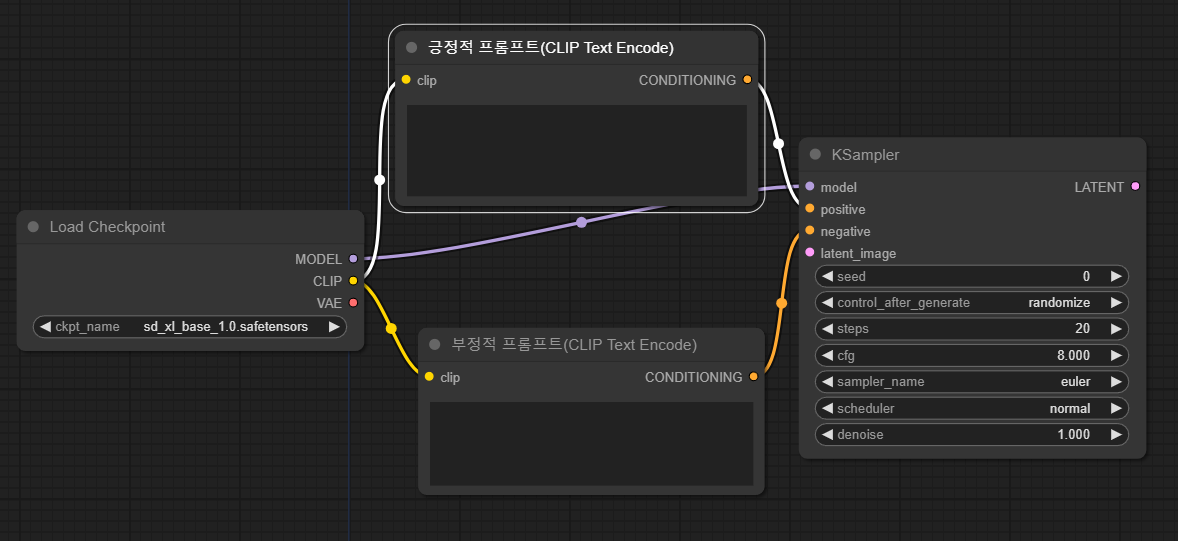
프롬프트 노드를 보면, 체크포인트 파일에 들어 있는 CLIP 모델을 사용해 사용자가 입력한 텍스트(프롬프트)를 번역해서 샘플링 알고리즘에 제공한다는 것을 알 수 있습니다.
잠재 이미지(latent image) 노드 추가
다시 KSampler로 되돌아가보면, 왼쪽에 주황색 latent_image 슬롯이 아직 아무데도 연결되어 있지 않습니다. 이 글에서는 간단히 아무것도 없는 비어있는 이미지(EmptyLatentImage)를 선택합니다. 마찬가지로 latent_image 슬롯을 드래그한 후 빈 캔버스에 떨어뜨리고 선택하면 됩니다.
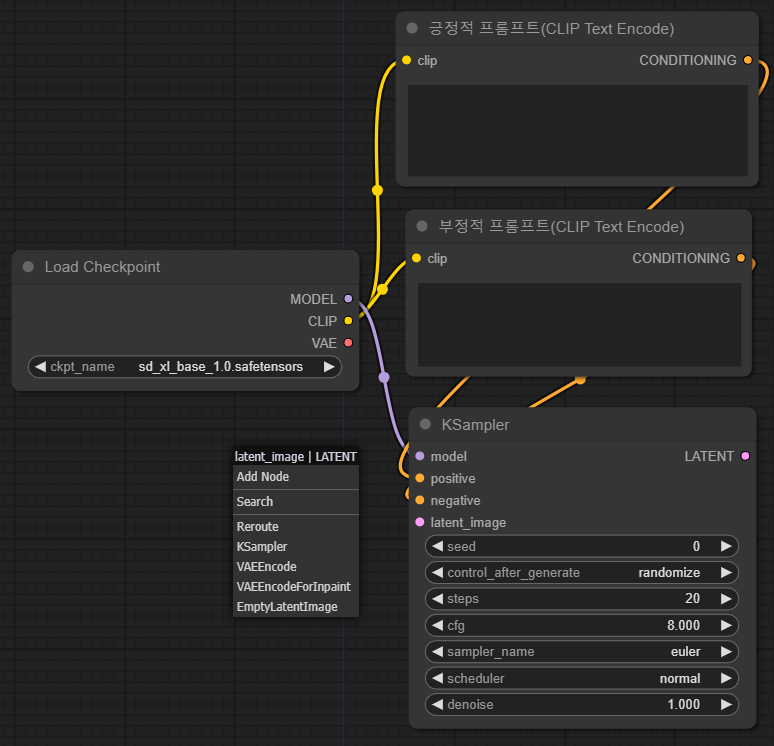
아래는 EmptyLatentImage 노드를 추가한 결과입니다. 우리는 SDXL을 사용하므로, 이미지 크기를 1024x1024로 설정해 주었습니다. 이렇게 해서 KSampler의 입력 슬롯은 모두 해결되었습니다.
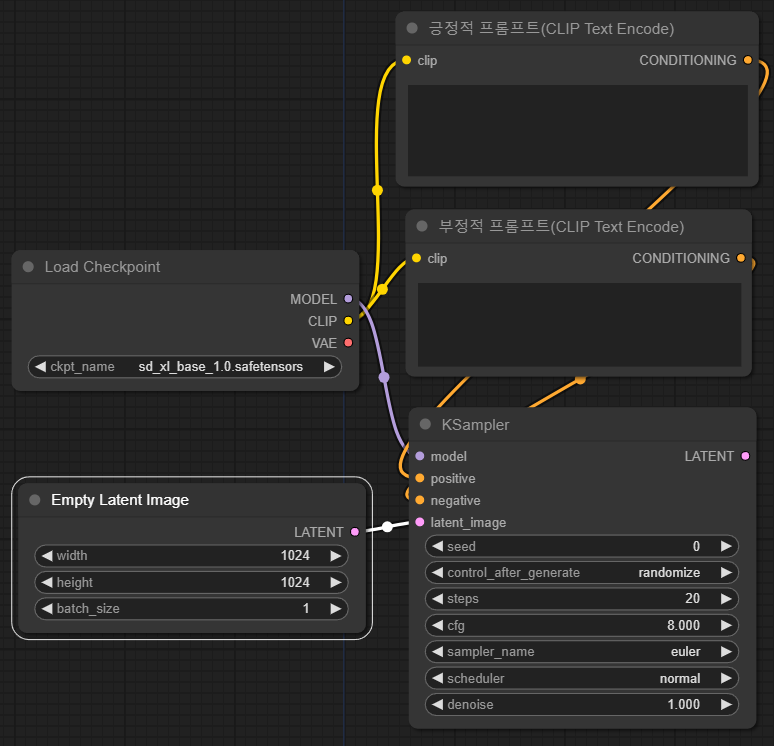
현재는 잠재 이미지를 빈 이미지(무작위 잡음)로 입력했지만, 대신 어떤 이미지를 제공해줄 수도 있습니다. 그러면 그 이미지를 초기 잡음으로 사용하여 이미지를 생성하게 되죠. 이 과정이 img2img입니다. AUTOMATIC1111에서는 text2img와 img2img가 완전히 다른 절차로 보이지만, ComfyUI에서는 그저 초기 이미지만 다르다는 것을 쉽게 알 수 있습니다.
VAE와 결과 이미지
이제 거의 끝이 보입니다. 지금 남아있는 것은 KSampler 노드의 오른쪽 분홍색 LATENT 슬롯만 남아 있습니다. 여기가 샘플링을 거쳐 만들어진 잠재 이미지(latent imge)를 진짜 이미지로 변환해 주는 곳입니다.
분홍색 "LATENT" 슬롯을 좌클랙-드래그 해서 캔버스에 떨어뜨리고 아래 그림과 같이 "VAEDecode" 노드를 선택합니다.
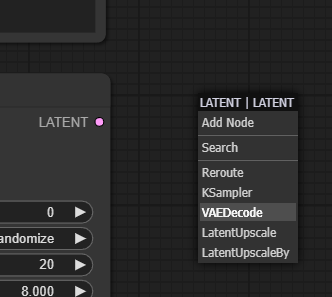
새로 추가된 VAE Decode 노드의 왼쪽편에는 samples와 vae, 두개의 입력 슬롯이 있습니다. samples는 KSample 노드에 자동으로 연결됩니다. 연결되지 않은 vae는 체크포인트 로드 모듈에 있는 VAE 슬롯에 연결해줍니다.
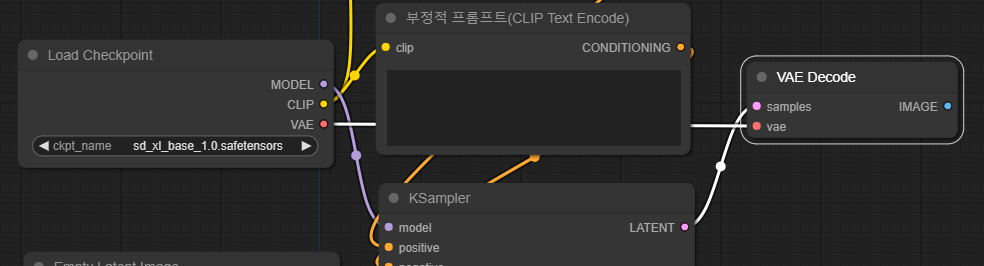
VAE(가변 자동 인코더, Variable Automatic Encoder)는 잠재 이미지를 실제 이미지로 바꿔주는 역할을 하며, 이것은 원래 체크포인트 파일의 일부임을 알 수 있습니다. 이 VAE를 이용해 VAE Decoder모듈이 이미지를 생성합니다.
VAE Decode의 오른쪽에 있는 하늘색 IMAGE 출력노드를 좌클릭-드래그한 후 아래와 같이 PreviewImage 노드를 선택해줍니다.
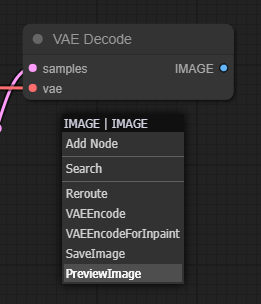
축하합니다. SDXL base모델을 사용하여 이미지를 생성할 수 있는 워크플로가 이제 완성되었습니다. 위치는 약간씩 다를 수 있는데, 전체적인 연결상태는 아래와 동일해야 합니다.
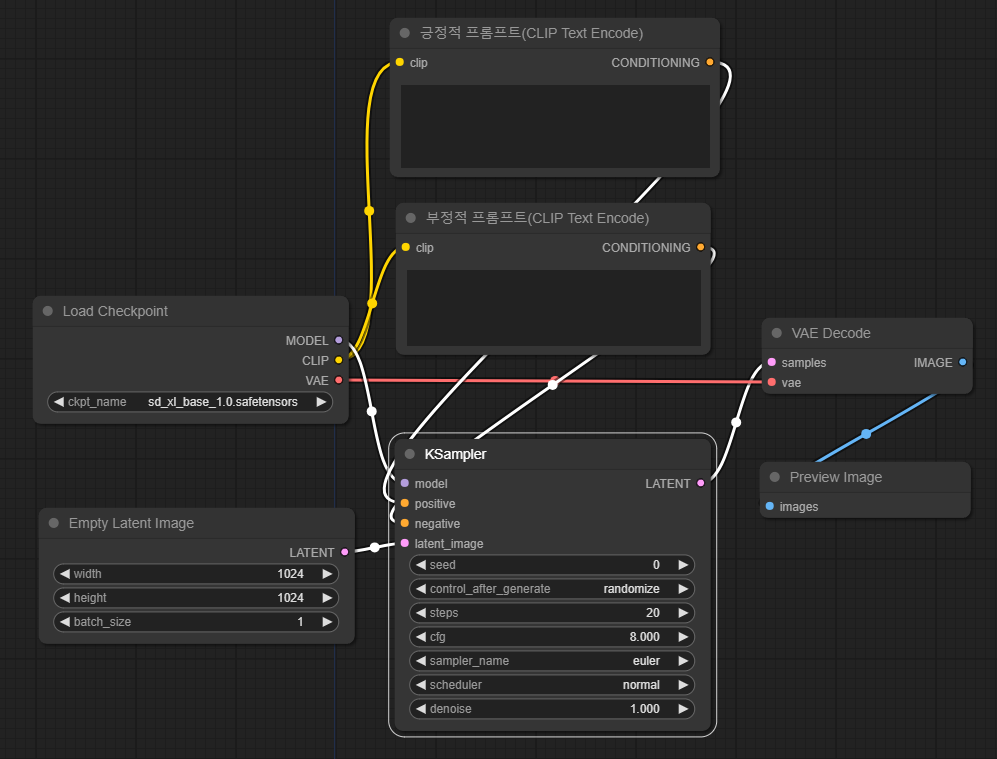
이제 이미지를 생성해 보겠습니다. 긍정적 프롬프트 노드에 프롬프트를 입력하고 맨 오른쪽에 있는 메뉴에서 "Queue Prompt" 버튼을 누릅니다. 저는 "a cat in a hat"이라는 프롬프트를 입력했지만, 어떤 프롬프트이든지 관계 없습니다. 잠시후 아래와 같이 생성된 이미지가 표시됩니다.
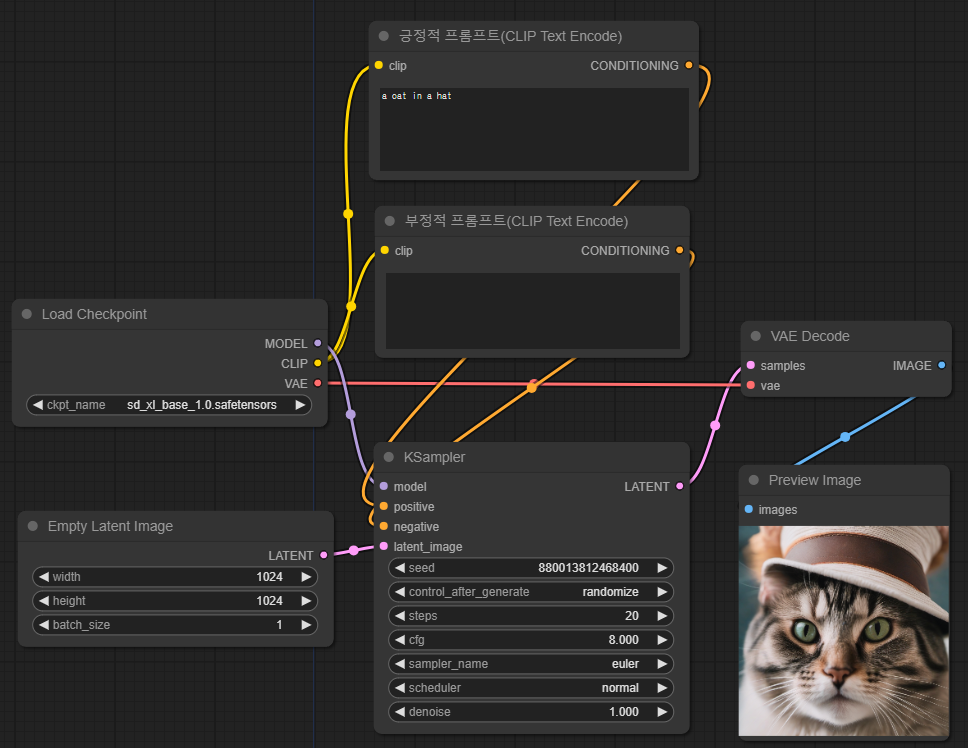
생성된 이미지 브리뷰 위에서 우클릭을 하면 이미지를 저장할 수 있습니다.

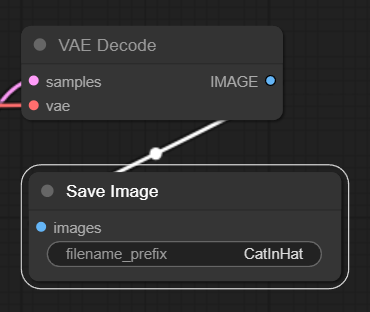
참고로 이렇게 프리뷰만 보지 않고 생성되는 이미지를 자동으로 추가하려면 Preview Image 노드 대신 Save Image 노드를 추가하면 됩니다. 이때 아래처럼 filename_prefix가 나오는데 생성되는 이미지 명이 이 단어로 시작됩니다. 자동으로 저장되는 폴더는 comfyUI\ComfyUI_windows_portable\ComfyUI\output 입니다.
이때 저장되는 위치를 바꾸고 싶으시다면 여기를 참고하시면 됩니다.
이상입니다. ComfyUI를 사용하면 AUTOMATIC1111을 사용할 때보다 확실히 스테이블 디퓨전에 대한 이론에 대해 잘 알게 되는 것 같습니다. 참고로, 아래 이미지를 다운로드 받은 뒤, ComfyUI의 캔버스에 드래그&드롭하면 위에서 만든 워크플로를 불러 들일 수 있습니다.

민, 푸른하늘
이 글은 https://followfoxai.substack.com/p/part-1-sdxl-in-comfyui-from-scratch 을 번역하면서 일부는 편집하여 작성한 글입니다.
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 초보자 가이드
- ComfyUI를 위한 유용한 정보
- ComfyUI 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기