ComfyUI는 다재다능한 오픈소스 이미지 생성형 AI인 스테이블 디퓨전을 위한 GUI중 하나입니다. 원래는 AUTOMATIC1111이 훨씬 더 많이 사용되었지만, 여러가지 워크플로를 쉽게 생성하고 변경할 수 있어서 사용자가 급격하게 늘어나는 중입니다.
다만, ComfyUI는 스테이블 디퓨전의 기술적인 내용과 많은 관련이 있어서 사용하기가 쉽지 않습니다. 요즘 들어 ComfyUI 에 관한 글이 더 많아졌는데, 사용법이 잘 정리된 문서가 없어서 고민하던 중이었는데, 이 투토리얼은 아주 기초적인 내용부터 고급 사용법까지 아우르는 여러가지 내용을 담고 있습니다. 처음부터 따라해보면 ComfyUI를 좀 더 확실하게 이해하실 수 있게 될 것입니다.
이 투토리얼은 Open.ai 의 ComfyUI Academy 에 올려진 11개의 유튜브 내용을 나름 편집해 정리한 것입니다. 따라서 이 글을 읽으신다면 해당 유튜브를 보면서 읽는 것을 추천드립니다.
이 튜토리얼은 모두 세편으로 이루어져 있습니다.
- ComfyUI 튜토리얼-1 : 유튜브 1~4편
- ComfyUI 튜토리얼-2 : 유튜브 5~8편
- ComfyUI 튜토리얼-3 : 유튜브 9~11편
아래는 이 글의 목차입니다.
레슨 5 : 마술 같은 Img2Img 와 WD14
유투브는 여기를 보세요
기본 img2img
아래는 이 레슨에서 사용하는 Img2Img 워크플로입니다. 이 워크플로는 레슨 4에서 사용한 워크플로와 거의 비슷합니다. 달라진 것은 이미지 크기를 변경시키는 [Image Resize] 가 추가되었을 뿐입니다.
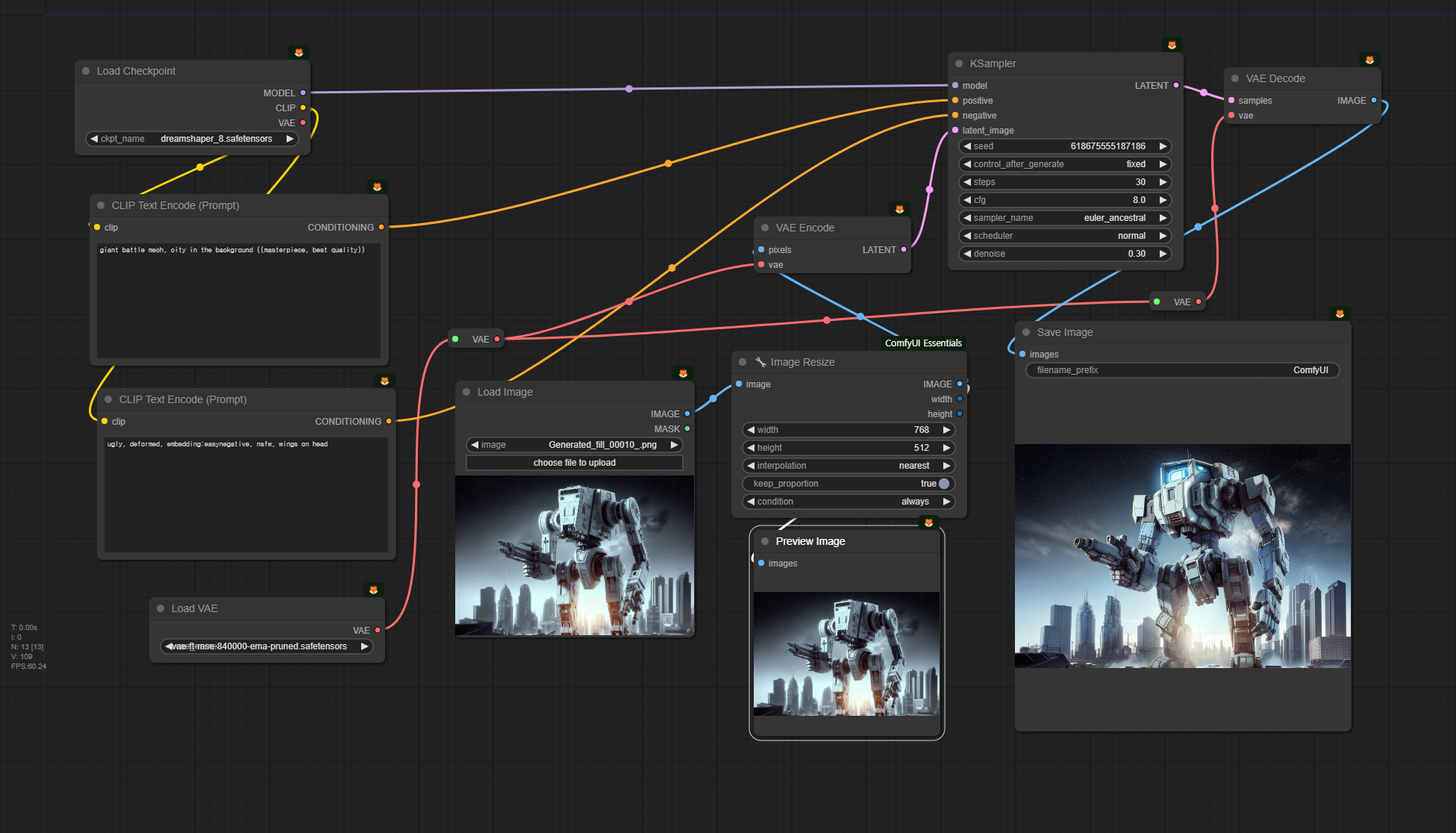
아래는 이 워크플로에서 사용하는 입력 이미지 입니다. 참고로 이 이미지는 MS Copilot을 통해 생성해서 자동 인페인트/아웃페인트 워크플로를 사용해 생성한 이미지입니다.

아래는 이 워크플로를 그대로 사용해 생성한 이미지입니다. 디테일은 다르지만 전체적으로 비슷한 형태의 거대 전투 로봇이 생성되었습니다. 이렇게 비슷한 이미지가 생성된 것은 잡음제거 강도(denoise)를 0.3으로 상당히 낮게 설정하였기 때문입니다.
 |
 |
아래는 잡음 제거 강도를 0.7로 올리고 생성한 결과입니다. 완전히 다른 형태의 휴머노이드 스타일의 로봇이 생성되네요.
 |
 |
그런데 위의 워크플로에서 주목할 점이 있습니다. 중간에 있는 [Image Resize] 노드입니다. 이 노드는 ComfyUI Essentials라는 커스톰 노드에 들어있는 노드라는군요. 이렇게 어느 커스톰노드에 속하는지를 표시하는 방법은 여기를 읽어보세요.
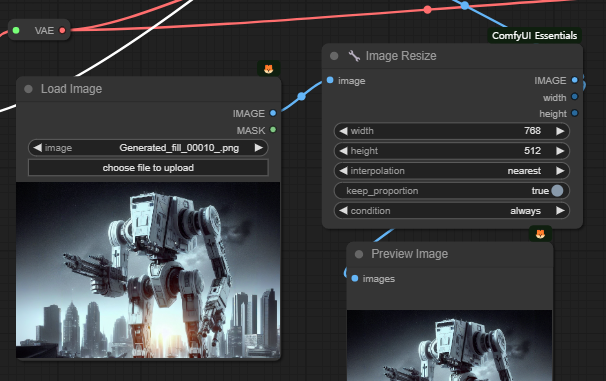
현재는 입력된 이미지와 출력된 이미지의 종횡비가 같도록 설정되어 있는데, 아래와 같이 종횡비를 바꿔주고 비율 유지를 취소 시키면, 아래 위로 길쭉하게 늘어진 이미지가 생기게 됩니다.

그래서 이렇게 생성을 하면 (잡음 제거 강도는 0.7) 아래와 같이 건담스타일 로봇이 생성됩니다.
 |
 |
프롬프트가 없는 img2img
아래는 비슷한 기능을 하지만, 프롬프트를 입력하지 않고 입력된 이미지로부터 자동으로 생성하는 워크플로입니다. 참고로 이 워크플로를 불러 들일 때 노드가 빨갛게 표시된다면, 해당 커스톰 노드가 설치되지 않았다는 뜻으로 여기를 읽어보면 해결할 수 있습니다.

이 워크플로에서 가장 중요한 부분은 프롬프트를 처리하는 부분입니다. 아래 그림 맨 오른쪽에 있는 [CLIPText Encode] 는 원래 텍스트를 입력하는 widget이 있었지만, 이것을 외부에서 받아들이도록 슬롯으로 바꿨습니다.

그런데 n>[CLIPText Encode]n> 에 입력되는 텍스트가 생성되는 구조를 보면 [Load Image] -> [WD14 Tagger] -> [String Function] -> [CLIPText Encode] 순으로 연결되어 있습니다. 여기에서 [WD14 Tagger]n> 노드는 [Load Image]의 이미지를 받아 분석해 프롬프트를 생성하는 역할을 합니다(AUTOMATIC1111의 Interrogate 와 비슷합니다). 입력된 로봇 "weapon, sky, gun, no humans, night, robot, building, mecha, science fiction, city, realistic, cityscape, arm cannon, gatling gun" 이라고 해석을 했네요.
그 다음에 있는 [String Function] 노드는 앞서 [WD14 Tagger] 노드에서 생성한 프롬프트와 직접 입력해둔 텍스트 "style of concept art, masterpiece, digital paiting, facing viewer" 을 결합(Append)한 텍스트를 만드는 역할을 합니다. [String Function] 노드의 맨 아래에는 이 두가지 텍스트를 결합하여 "weapon, sky, gun, no humans, night, robot, building, mecha, science fiction, city, realistic, cityscape, arm cannon, gatling gun, style of concept art, masterpiece, digital paiting, facing viewer"라는 텍스트를 생성했습니다. 최종적으로 이렇게 생성된 텍스트 프롬프트가 [CLIPText Encode] 에 입력으로 들어가는 것입니다.
아래는 위의 워크플로로 생성한 이미지입니다.
 |
 |
 |
이상에서 보시는 것처럼, 이 워크플로는 프롬프트를 별도로 입력해주지 않습니다. 물론 [String Function] 노드에서 "style of concept art, masterpiece, digital paiting, facing viewer"를 입력하긴 했지만, 이것은 범용 프롬프트로 생각하면 됩니다.
이번엔 아래 왼쪽의 여성 이미지를 입력하고 그냥 [Queue Prompt] 를 눌렀을 때의 결과입니다(아래 중간). 보시는 것처럼 아무 프롬프트를 조정하지 않았음에도 왼쪽 이미지를 바탕으로 새로운 스타일의 이미지를 생성했습니다. 여성의 자세, 소파, 그리고 스텐드의 위치를 보면 상당히 원 이미지를 반영했음을 알 수 있습니다. 참고로 맨 오른쪽은 잡음제거 강도(denoise)를 0.3으로 낮게 잡았을 때의 결과로 원본 이미지와 거의 비슷함을 알 수 있습니다.
 |
 |
 |
레슨 6 : 모델 바꿔치기 및 마스킹
유튜브는 여기를 보세요.
모델 바꿔치기
아래는 두가지 모델을 사용하여 두번 샘플링하는 워크플로입니다.

위의 워크플로에서 가장 중요한 부분은 [KSampler] 노드가 두개 있는데, 첫번째 [KSampler] 노드에서 나온 결과를 두번째 [KSampler]에서 받아 다시 한번 샘플링하는 부분입니다. 사실 이렇게 [KSampler] 노드가 두개 있는 경우는 레슨 3: 잠재 이미지 확대에서도 보았으므로 처음은 아닙니다. 다만 여기에서는 앞쪽과 뒤쪽 노드가 각각 다른 모델을 사용한다는 점이 독특합니다. 즉, 앞쪽 [KSampler]n> 노드는 revAnimated 모델을, 뒤쪽 [KSampler] 노드는 epicRealism 모델을 사용합니다.
참고로 이 워크플로 맨 왼쪽에는 아래와 같이 [CLIP Set Last Layer] 가 있는데, 애니 모델의 경우에는 -2로, 일반 모델의 경우에는 -1로 두는 것(기본값입니다)이 좋다고 합니다.

아래는 위 워크플로에서 프롬프트 부분만 따로 잘라본 것입니다. 부정적 프롬프트는 일반 [CLIP Text Encode] 노드를 사용했지만, 긍정적 프롬프트는 [CR Prompt Text]를 통해 텍스트만 입력한 후, 두개의 [KSampler] 노드에 각각 별도의 n>[CLIP Text Encode] 노드를 연결해 넣어주었음을 알 수 있습니다. 이렇게 한 이유는 사용하는 CLIP 모델이 다르기 때문입니다. 또 오른쪽에 있는 두개의 [KSampler] 노드 사이에는 [Upscale Latent By] 노드가 있어서 잠재 이미지가 1.5배 확대됨을 알 수 있습니다.
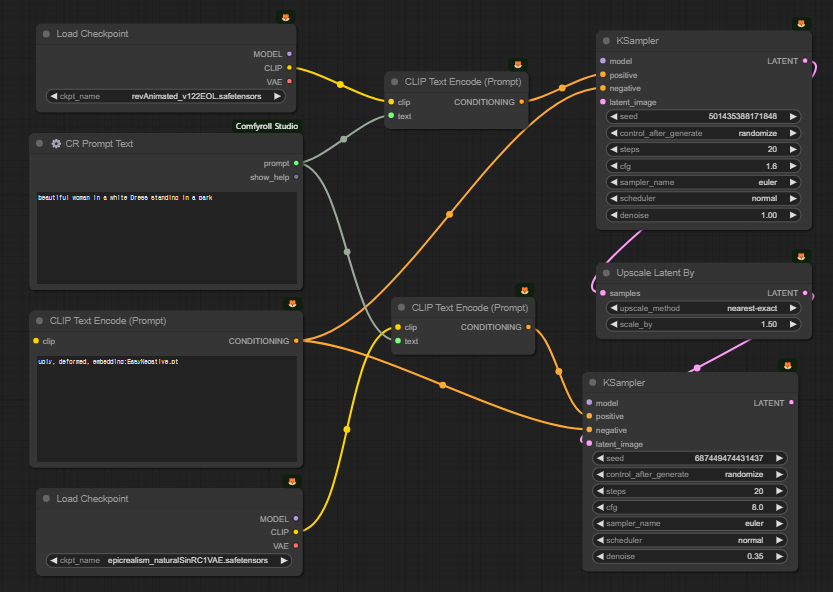
기본적으로 이 워크플로는 두 개의 체크포인트 모델을 사용하는 방법입니다. 이렇게 두개의 모델을 사용하는 이유는 revAnimated 모델이 색감과 구도가 좋게 나오기 때문에 사용한 것이고, 이렇게 생성된 이미지를 n>epicRealism 모델을 사용해서 실사 사진에 가깝게 만들고자 하는 것이라고 합니다.
아래는 생성된 결과입니다. 왼쪽은 revAnimated 만 사용한 결과이고, 오른쪽은 두번째로 epicRealism 모델을 적용한 결과입니다.
 |
 |
이렇게 워크플로를 자유롭게 설정할 수 있는 것이 ComfyUI의 매력이라고 할 수 있습니다. 만약 이것을 AUTOMATIC1111에서 똑같이 실행시키려면, 먼저 txt2img 페이지에서 n>revAnimated 를 사용해서 생성하고, 그 결과를 img2img 로 보내기 버튼을 눌러서 img2img 페이지에 넣은 후, HiRes Fix를 활성화시켜 1.5배로 확대하고, 모델을 epicRealism 모델로 바꿔서 다시 생성하는 과정을 거쳐야 했을 겁니다. 완전 번거러웠겠죠.
이미지 마스크 사용법
아래는 이미지 마스크를 지정해서 얼굴을 새로 그리는 인페인트(inpaint) 워크플로입니다.

인페인트를 위해서는 마스크(새로 그릴 부분)를 지정해야 합니다. 마스크를 생성하는 방법은 간단합니다. [Load Image] 노드에서 이미지를 우클릭하면 긴 메뉴가 나오는데, 거기서 "Open in MaskEditor] 를 선택하면 아래와 같은 창이 열립니다. 여기에서 바꾸고자 하는 부분을 그려준 후, 맨 마지막에 오른쪽 아래의 [Save to node] 버튼을 클릭면 됩니다. 저는 얼굴과 드레스 뒤쪽이 날리는 부분을 마스크로 지정했습니다.

아래는 이 워크플로를 실행시킨 결과입니다. 맨 왼쪽은 원본이고, 오른쪽 두개는 인페인트를 적용한 결과입니다. 참고로 이 워크플로에서 프롬프트는 "beautiful woman, wearing glasses"로 지정했는데, 이처럼 인페인트로 다시 그릴 부분에 대해서만 프롬프트를 지정하는 것이 좋습니다.
 |
 |
 |
아래는 이 인페인트 워크플로에서 가장 중요한 부분인 입력된 이미지로부터 [KSmapler] 노드에 이르기 까지 과정만 따로 분리해본 것입니다.
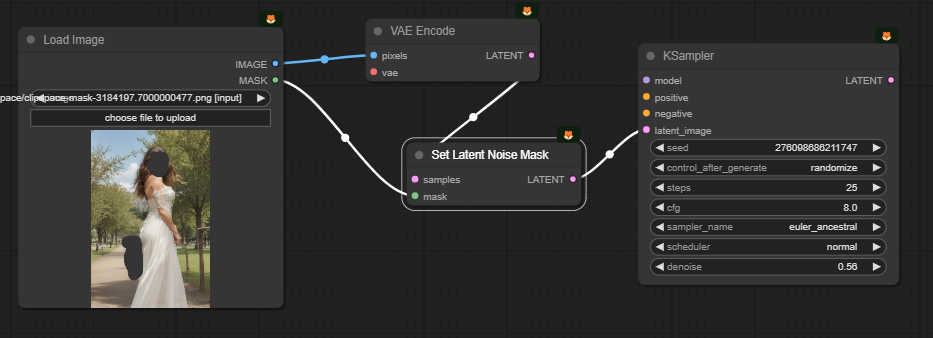
위쪽의 [VAE Encode]는 마스크 하기전의 이미지를 잠재 이미지로 변환합니다. [Set Latent Noise Mask] 노드는 이 잠재 이미지와 [Load Image]에서 생성한 마스크를 합쳐서, 마스크가 존재하는 잠재 이미지로 만들어 [KSampler] 노드로 넘겨주는 것입니다.
참고로 ComfyUI 예제 사이트의 Inpaint 예제에서는 [VAE Encode]와 [Set Latent Noise Mask] 노드 역할을 합친 [VAE Encode (for inpainting)] 노드를 사용하고 있는데, 이 노드를 사용하면 아래 이미지처럼 인페인트가 잘 안되는 경우가 많습니다. (인페인트 전용 체크포인트 모델을 사용할 때에는 이런 현상이 발생하지 않습니다)
 |
 |
 |
레슨 7 : 실시간 모델 합치기(Merge)
유튜브는 여기를 보세요.
아래는 두가지 실시간으로 모델을 합쳐서 사용하는 워크플로입니다.

먼저 모델, 정확히는 체크포인트(checkpoint) 모델은 이미지를 학습한 결과를 담고 있는 가중치(weight) 파일입니다. 이러한 체크포인트 파일은 civitai.com에 들어가면 여러가지 스타일의 모델을 엄청나게 많이 찾을 수 있습니다. 모델에 관한 좀 더 자세한 사항은 모델에 관한 모든 것을 읽어보시기 바랍니다.
이 워크플로에서도 [KSampler]를 두번 실행시킵니다. 아래에서 좌우를 비교해보면, 샘플러를 다른 것(euler_ancestral과 dpmpp_2m_sed)을 사용하였고, 또한 잡음제거 강도가 처음은 1.0, 나중은 0.55를 적용하였음을 알 수 있습니다.
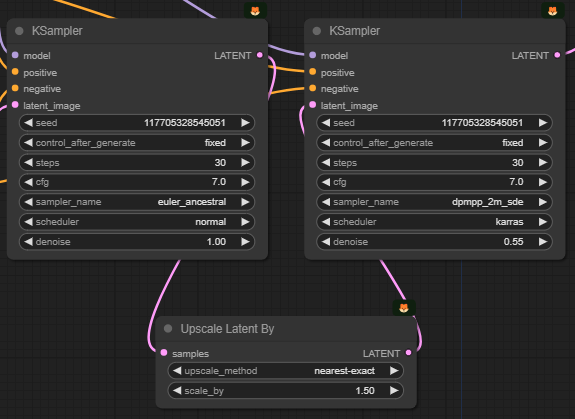
아래는 이 워크플로에서 가장 중요한, 모델을 합치는(Merge) 부분입니다. 그런데 보시는 것처럼 아주 간단합니다. [ModelMergerSimple] 노드는 체크포인트 모델을 합치과, [CLIPMergerSimple] 노드는 CLIP 모델을 합치는 것 뿐입니다. 합치는 비율을 ratio로 지정하게 되어 있구요.

아래는 ratio를 달리하면서 두개의 모델을 합쳐서 생성한 결과입니다. 프롬프트는 "beautiful japanese woman in a business dress, slender, standing in a japanese bar" 입니다.
여기에서 ratio는 model1으로 지정된 모델이 차지하는 비중으로서, 0.2로 지정하면 epicRealism : revAnimate = 2 : 8 이라는 뜻입니다. 아래에서 두 모델이 차지하는 비율이 달라지는 효과를 보실 수 있을 것입니다.
 |
 |
 |
| ratio = 0.0 | ratio = 0.2 | ratio = 0.4 |
 |
 |
 |
| ratio = 0.6 | ratio = 0.8 | ratio = 1.0 |
이처럼 모델을 서로 실시간으로 합치면서 결과를 비교할 수 있기 때문에 이 기능은 매우 쓸만 합니다. 게다가 이 방법을 조금만 더 확장하면 세개 네개의 모델도 합칠 수 있습니다. 물론 RAM의 용량에 제한을 받겠지만요. ㅎㅎ
AUTOMATIC1111과의 비교
AUTOMATIC1111의 경우에는 이와 같이 실시간으로 모델을 합치는 기능이 없습니다. 물론 모델을 합치는 기능은 있지만, 물리적인 파일로 생성해야 하는 거죠. 그러므로 만약 위와 같이 생성해보려면, 0.2/0.4/0.6/0.8 비율로 모델을 생성하여야 하므로 거의 10GB 에 해당하는 저장공간이 낭비될 수 밖에 없습니다.
또 한번 ComfyUI가 쓸만하다는 걸 알게 되었네요.
레슨 8 : ComfyUI 에서 LoRA 사용법
유튜브는 여기를 보세요.
LoRA란?
LoRA(Low-Rank Adaptation, 저 랭크 적응?)은 Stable Diffusion 모델을 세부 조정하기 위한 학습 기법입니다. 용량이 큰(2Gb 이상) 체크포인트 모델을 훈련시키는 대신 LoRA를 이용하면 적은 용량(수백 Mb)으로 비슷한 기능을 수행할 수 있어 널리 사용되고 있습니다.
LoRA 모델도 체크포인트 모델과 마찬가지로 Civitai.com에 많습니다. 먼저 https://civitai.com/models 에 들어가서 오른쪽에 있는 필터(Filters)를 누르면 원하는 모델만 볼 수 있습니다. 아래는 SD1.5용 LoRA만 필터링하는 예입니다.

LoRA는 LoRA에 따라 성능이 발휘하는 조건이 다릅니다. 가장 중요한 것은 체크포인트 모델과의 조화입니다. 해당 LoRA의 스타일을 잘 드러내주는 체크포인트 모델이 있다는 것입니다. 또한 아래 그림에서 보는 것처럼 LoRA 파일을 발현시켜주는 "Trigger Words"가 따로 있는 경우가 있는데, 이때는 프롬프트에 해당 단어가 포함되어야 합니다. 아울러, CFG 값이나 가중치(weight)등도 중요할 수 있습니다. 이러한 사항은 대개 LoRA 파일 사이트에 적혀있으니 가능하면 찾아서 적용하는 것이 좋습니다.

이 유튜브를 제작한 분이 추천하는 LoRA는 아래와 같습니다
- Add More Detail - 생성되는 이미지에 미세한 디테일을 추가하거나 줄일 수 있습니다.
- Promised Neverland - 애니 스타일을 표현해줍니다.
- Nier Automata Anime - Nier Automata라는 비디오게임 스타일이랍니다.
- Skin & Hands - 노화된 피부 등 좀 더 현실적인 피부를 지정할 수 있습니다.
- Evangeline Lilly - 여 배우를 학습시킨 모델입니다.
기본적인 LoRA 사용법
아래는 LoRA를 사용하기 위한 워크플로입니다.

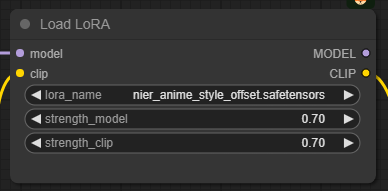
아래는 위의 LoRA 워크플로중에서 윗부분에 있는, 단독 LoRA 사용법입니다. 적용 순서는 [Load Checkpoint] -> [CLIP Set Last Layer] -> [Load LoRA] -> [CLIP Text Encode] 로 연결하면 됩니다.

또한 [Load Lora] 노드에는 아래와 같이 LoRA에 대한 가중치(strength_model)과 CLIP에 대한 가중치(strength_clip)이 있으니 적절하게 조절할 수 있습니다.
LoRA STACK
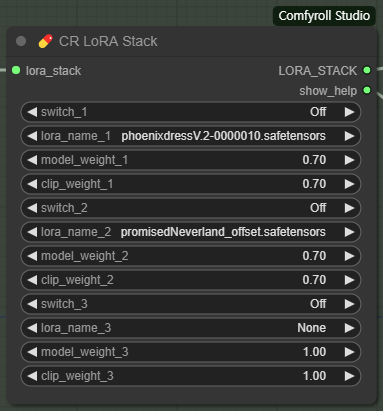
위의 워크플로 아래쪽에는 여러개의 LoRA를 한꺼번에 지정할 수 있는 [CR Loara Stack] 과 [CR Apply LoRA Stack] 노드를 사용하고 있습니다. 사용방법은 [Load Checkpoint] -> [CLIP Set Last Layer] 다음에 [CR Apply Lora Stack] -> [CLIP Text Encode]로 연결하고, [CR Loara Stack] 은 [CR Apply LoRA Stack] 에 연결해 주면 됩니다.
아래에서 보시는 것처럼 [CR Loara Stack]은 얼마든지 연결해 사용할 수 있지만, 너무 많으면 오히려 원하는 효과를 얻을 수 없을 가능성이 높으므로 5개 정도를 한계로 생각하면 좋습니다.

[CR LoRA Stack] 노드에는 각각의 LoRA를 끄거나 켤수 있는 switch가 있고, 아래쪽에 모델 및 CLIP에 대한 가중치를 설정할 수 있습니다.
아래는 add_detail LoRA와 cuteGirlMix LoRA를 사용해 생성한 결과입니다.
 |
 |
 |
원 비디오에 들어가보시면 phoenixdress 등 다른 LoRA를 여러가지 조합해서 생성하는 결과가 있으니 참고하세요.
이상입니다. 이 글은 OpenArtFlow 의 ComfyUI Academy에 있는 유튜브 5~8편을 사용하여 제 마음대로 편집하여 작성하였습니다.
민, 푸른하늘
====
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 투토리얼
- ComfyUI를 위한 유용한 정보
- ComfyUI와 SDXL 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기