Text-to-video는 말 그대로 입력한 텍스트 프롬프트만 사용해 비디오를 생성하는 기법입니다. 디퓨전 기반의 text-to-video 모델은 매우 빠른 속도로 발전하고 있습니다. 이 글에서는 자신의 PC에서 직접 사용할 수 있는 text-to-video 모델 중 가장 유명한 것중 하나인 AnimateDiff를 소개(논문: AnimateDiff:Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning, Yuwei Guo 등)하고 그 작업과정을 보여드립니다.
참고: 2023년 12월, Stable Video Diffusion이 공개되었습니다. txt2vid, img2vid는 SDV를 사용하는 것이 더 빠르고 품질이 좋습니다.(https://www.internetmap.kr/entry/Stable-Video-Diffusion-official-img2vid)
AnimateDiff는 스테이블 디퓨전을 사용해 비디오를 생성하는 방법중 가장 쉬운 방법입니다. 가장 간단하게라면 모델 설정하고 AnimateDiff를 켠 상태에서 그냥 프롬프트만 넣으면 비디오가 생성됩니다.
AnimateDiff 가 생성하는 최종 비디오는 아래와 같습니다.

이 글에서 다루는 내용은 다음과 같습니다.
- AnimateDiff의 원리
- Software
- AimateDiff 비디오 생성하기
- 고급 옵션
- AnimateDiff를 사용한 video-to-video
- Motion LoRA
- Image-to-Image
- AnimateDiff 프롬프트 travel
- HiRes. Fix 를 사용한 해상도 증가
- AnimateDiff v3
- SDXL용 AnimateDiff
- AnimateDiff 속도 올리기
- 결론
- 예전 예제
AnimateDiff의 원리
AnimateDiff 는 스테이블 디퓨전을 위한 Text-to-Video 모델입니다. 일반적인 text-to-image 기법의 확장이라고 할 수 있습니다. 이미지 대신 비디오를 생성하는 것입니다.
AnimateDiff의 작동 방식
AnimateDiff는 control module을 사용하여 스테이블 디퓨전 모델에 영향을 줍니다. 이 모델은 짧은 비디오 클립을 입력하여, 다음 비디오 프레임이 어떻게 바뀌어야 하는지를 학습시키는 방식으로 구축되었습니다. 이 control module 은 이미지 생성 프로세스에서 조건부여(conditioning)로 작용하여, 자신이 학습한 비디오 프레임과 비슷한 여러장의 이미지를 생성합니다.
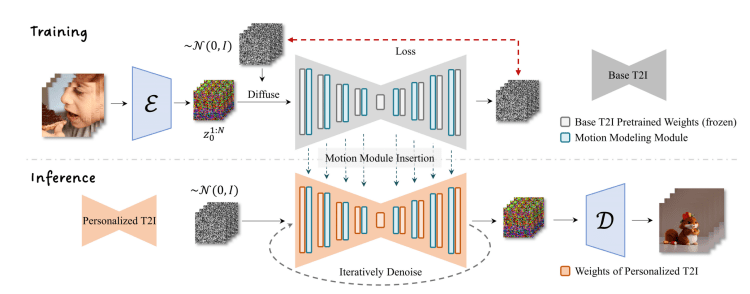
ControlNet과 마찬가지로 AnimateDiff의 콘트롤 모듈은 어떠한 Stable Diffusion 체크포인트 모델에도 적용할 수 있습니다. 단, 현재는 Stable Diffusion v1.5 모델과 SDXL 모델 모두 지원하는데, SDXL용 AnimateDiff 모델은 beta 버전입니다.
AnimateDiff 의 한계
AnimateDiff는 학습데이터로부터 학습한 움직임을 따르므로, 일반적으로 나타나는 전형적인 움직임을 만들어 냅니다. 따라서, 프롬프트에서 일련의 자세한 움직임을 따르도록 지시할 수 없습니다.
또한 움직임의 품질도 학습데이터에 민감합니다. 학습데이터에 존재하지 않는 이국적인 그래픽은 애니메이션을 만들어 내기가 힘듧니다. 즉, 주제나 스타일에 따라 품질이 달라질 수 있으니 주의하셔야 합니다.
아래는 자연스러운 움직임을 표현하도록 만드는 팁입니다.
- 비디오 생성과정동안 프롬프트를 변화시킵니다. 이 기법을 Prompt travel이라고 합니다.
- 참조 비디오와 함께 ControlNet을 사용한다.
이 글 뒤편에 이러한 기법을 시험한 부분이 있으니 참고하세요.
소프트웨어
이 글에서는 스테이블 디퓨전 GUI 중 하나로서, 가장 널리 사용되고 오픈소스 소프트웨어인 AUTOMATIC1111 을 사용합니다. AUTOMATIC1111이 처음이신 분은 설치방법과 초보자 가이드를 참고하세요.
AimateDiff 확장 설치 방법
AUTOMATIC1111에서 AnimateDiff를 사용하려면 먼저 AnimateDiff 확장을 설치해야 합니다.
1. AUTOMATIC1111 에서 Extension 페이지에 들어가서 Install from URL 탭을 클릭합니다.
2. [URL for extension's git repository] 필드에 아래의 URL을 입력하고, [Install] 버튼을 클릭합니다.
https://github.com/continue-revolution/sd-webui-animatediff
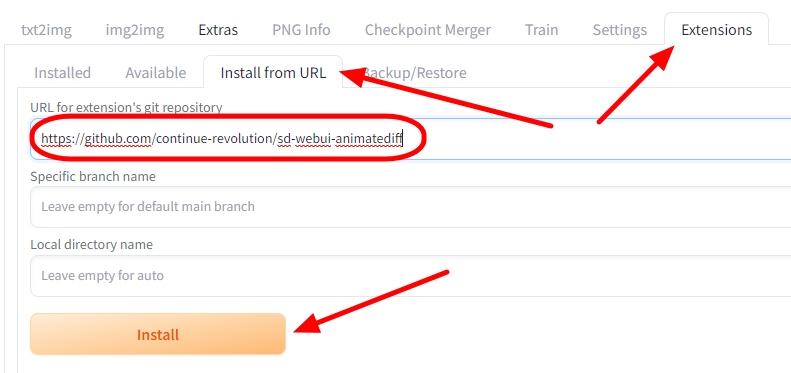
3. 설치가 완료되었다는 메시지가 나올때 까지 기다립니다.
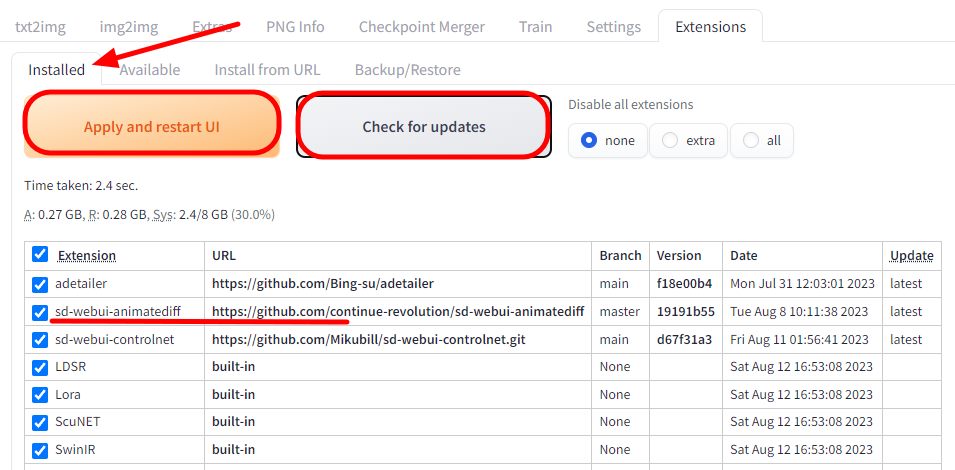
4. 마지막으로 [Installed] 탭으로 들어가서 정상적으로 설치되었는지 확인합니다. [Check for updates] 버튼을 눌러서 오른쪽에 다른 확장이 최선 버전인지 확인하고 마지막으로 [Apply and restart UI]를 눌러주면 됩니다.
참고로, animateDiff Github에 따르면, 추론 메모리 소모를 줄이기 위해 xformer 옵션을 넣어주라고 합니다. 참고하세요. xformer 옵션 사용법은 이 글을 읽어보시면 됩니다.
AnimateDiff 모션 모듈 다운로드
AnimateDiff를 사용하려면 적어도 1개의 모션 모듈을 다운로드 받아야 합니다. 모션모듈은 원 저자의 Hugging Face 페이지에 들어가면 있습니다.
대부분 최신 버전만 받으면 충분히 사용할 수 있습니다.
- https://huggingface.co/conrevo/AnimateDiff-A1111/blob/main/motion_module/mm_sdxl_v10_beta.safetensors
- https://huggingface.co/conrevo/AnimateDiff-A1111/blob/main/motion_module/mm_sd15_v3.safetensors
아래는 예전 버전입니다. 이 글에서는 v2 모델을 사용했는데, 바로위에 있는 v3 모델로 바꿔서 실행시켜도 됩니다.
- v1.4 모델: https://huggingface.co/guoyww/animatediff/resolve/main/mm_sd_v15.ckpt
- v1.5 모델: https://huggingface.co/guoyww/animatediff/resolve/main/mm_sd_v15.ckpt
- v2 모델 : https://huggingface.co/guoyww/animatediff/resolve/main/mm_sd_v15_v2.ckpt
다운로드 받은 파일은 stable-diffusion-webui\extensions\sd-webui-animatediff\model 폴더에 넣어주시면 됩니다.
AnimateDiff 로 비디오 생성하기
여기에서는 거실에서 새로운 갑옷을 입어보며 기뻐하는 여성의 비디오를 생성해 보겠습니다.

1단계: 스테이블 디퓨전 모델 선택
이 예제에서는 사실적인 인물을 사용하기 위해 CyberRealistic v3.3 모델을 사용합니다. 모델은 stable-diffusion-webui \models\Stable-Diffusion에 다운로드 받으시면 됩니다.
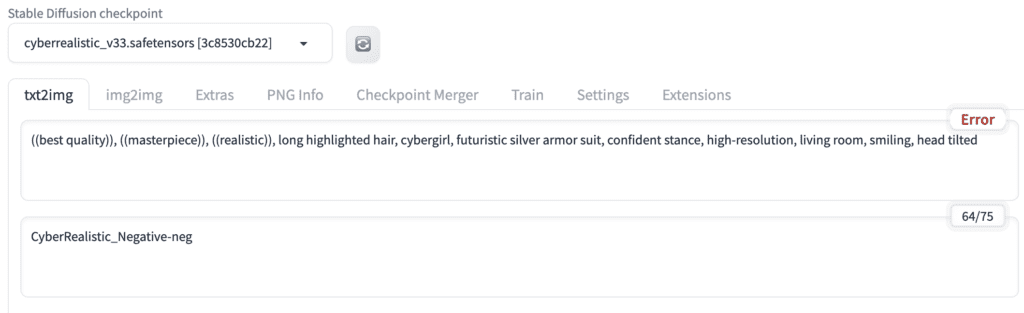
다운로드가 완료되면 아래 그림과 같이 Stable Diffusion checkpoint 드롭다운 메뉴에서 이 모델을 선택해 줍니다.
2단계: txt2img 설정
프롬프트: long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted, ((best quality)), ((masterpiece)), ((realistic))
부정적 프롬프트: CyberRealistic_Negative-neg (CyberRealistic 모델에 대한 부정적 embedding 입니다.)
단계수 : 20
샘플러 : DPM++ 2M Karras
CFG 척도 : 10
씨드 : -1
Size : 512x512
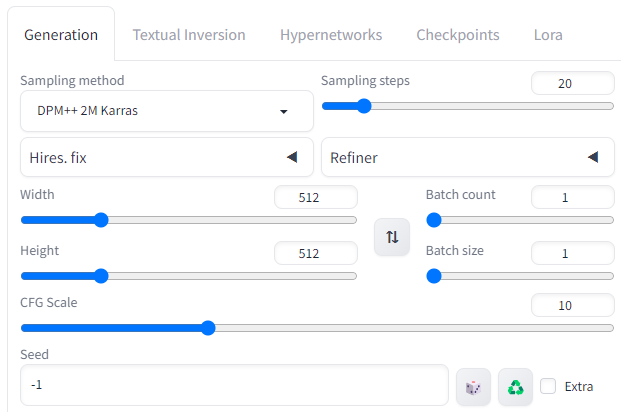
참고로, 한번에 여러개의 비디오를 만들려면 batch size가 아니라, batch count를 올려야 합니다.
3단계 : AnimateDiff 설정
txt2img 페이지에서 아래로 내려가면 AnimateDiff 영역이 있는데, 오른쪽 삼각형을 눌러 펴줍니다.
AnimateDiff 설정은 아래와 같습니다.
- Motion Module: mm_sd_v15_v2.ckpt
- Enable AnimateDiff: Yes
- Number of frames: 32 (비디오의 길이입니다.)
- FPS: 8 (초당 프레임 수입니다. 그러니까 비디오 길이는 32/8 = 4초가 됩니다)
나머지 설정은 그대로 두셔도 됩니다.
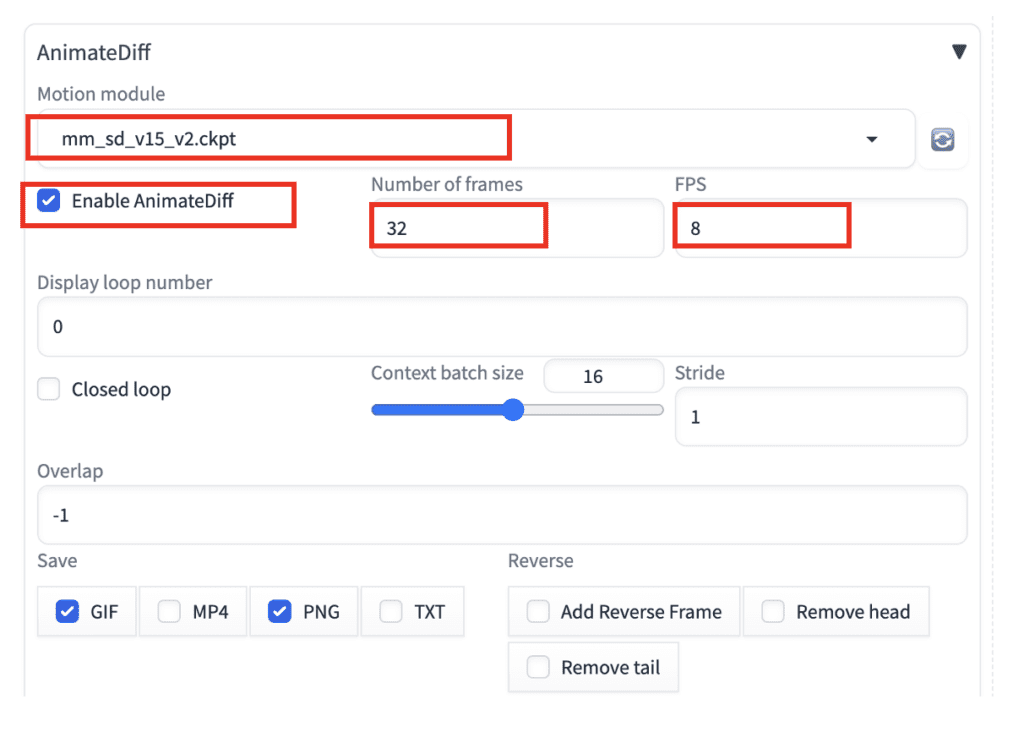
4단계: 비디오 생성
이제 [Generate] 버튼을 누르면 비디오가 생성됩니다. 아래는 이렇게 해서 생성된 gif 영상입니다. 보시는 것처럼 깔끔한 영상을 얻을 수 있습니다.

고급 옵션
참고로 좀 더 자세한 설명은 GitHub 페이지를 참고하세요. 아래는 예제를 포함한 간략한 설명입니다.
Close loop
close loop 옵션을 켜면 비디오가 연속적이 됩니다. 즉, 첫프레임과 마지막 프레임이 동일해져서, 끝부분에서 갑자기 튀는 현상이 사라집니다. 위에 생성된 비디오가 close loop를 선택해서 생성한 비디오입니다.
- N : Close loop 를 사용하지 않습니다.
- R-P : Close loop 콘텍스트를 줄입니다. 프롬프트 트래블(Prompt travel)에서는 Close loop를 내삽하지 않습니다.??
- R+P : Close loop 콘텍스트를 줄입니다. 프롬프트 트래블(Prompt travel)에서는 Close loop를 내삽합니다.??
- A : 마지막 프레임을 첫 프레임과 동일하게 합니다. 프롬프트 트래블(Prompt travel)에서는 Close loop를 내삽합니다.??


그런데 제 눈에는 그게 그거네요. ㅠㅠ
Frame interpolation
Frame interpolation 은 초당 프레임 수를 늘려서 비디오를 부드럽게 보이도록 만들어주는 옵션입니다.
옵션을 FILM으로 하는 경우, 프레임과 프레임 사이를 내삽해서 보다 부드러운 영상을 만들어 줍니다. 예를 들어, 아래처럼 설정할 경우, 원래의 초당 프레임이 8 인데, 4배를 해서 초당 32프레임이 되도록 중간을 채워서 더 부드러운 이미지를 생성해 줍니다.

단, 이때, FPS도 32 로 설정해야 올바르게 표현됩니다. 아니면 슬로모션으로 나타나게 됩니다.
아래는 이렇게 해서 생성한 영상입니다. 뭐 그런데... 그다지 큰 차이는 없어 보이네요.

Context batch size
Context batch size는 시간적 일관성을 제어하는 옵션입니다. 이 값을 높히면 비디오의 변화가 줄어듭니다.
하지만 16이 아닌 다른 값을 사용하면 비디오 품질이 나빠지네요. 16을 사용하는 것이 좋겠습니다.
 |
 |
 |
| Context batch 8 | Context batch 16 | Context batch 32 |
AnimateDiff를 사용한 Video-to-Video
AnimateDiff는 기본적으로 움직임을 제어할 수 없습니다. 그런데, ControlNet과 참조 비디오를 함께 사용하면 움직임을 제어할 수 있습니다.
먼저 예제를 먼저 보시겠습니다. 아래의 비디오를 참조 비디오로 사용해서, 이 분의 움직임을 따르도록 하는 것이 목표입니다.

1단계 : 비디오 업로드
txt2img 페이지에서 AnimateDiff 영역으로 내려간다음, 비디오 소스(Video source) 캔버스에 비디오를 업로드합니다.

2단계: AnimateDiff 설정
프레임 수(Number of frames)와 FPS (초당 프레임)는 비디오와 맞추하는데, 아래 값들은 자동적으로 설정됩니다.
- Number of frames): 96
- FPS : 29
다른 모든 설정은 위의 예와 동일합니다.
3단계: txt2img 설정
모델: cyberrealistic_v33.safetensors
프롬프트: ((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted
부정적 프롬프트: CyberRealistic_Negative-neg
샘플링 단계(steps): 20
샘플러 : DPM++ 2M Karras
이미지 크기 : 512x512
4단계: ControlNet 켜기
참조 비디오의 자세를 복제하려면 반드시 ControlNet을 활성화하여야 합니다. ControlNet 부분 오른쪽 삼각형을 눌러 펼친 다음, ControlNet Unit 0 영역에 아래와 같이 설정합니다.
- Enable: check
- Preprocessor: dw_openpose_full
- ControlType: OpenPose
4단계: 비디오 생성
이제 [Generate] 버튼을 눌러 비디오를 생성합니다. 아래가 Openpose를 사용한 AnimateDiff 비디오입니다.
반드시 Openpose 콘트롤넷을 사용하여야 하는 것은 아니고, 다른 콘트롤넷도 사용할 수 있습니다. 아래는 Canny Endge 감지기를 사용할 때 설정값입니다.
- Enable: Yes
- Preprocessor: Canny
- Model: Canny
- Control Weight: 0.75
또 아래는 Depth 모델을 사용할 경우의 설정값입니다.
- Enable: Yes
- Preprocessor: Depth Midas
- Model: depth
- Control Weight: 0.75
Motion LoRA
AnimateDiff에 Motion LoRA를 사용하면 카메라 움직임을 추가할 수 있습니다. 사용법은 일반 LoRA 사용법과 동일합니다.
Motion LoRA 다운로드
Motion LoRA 모델은 아래 링크에서 다운로드 받을 수 있습니다. 여기에서 이름에 lora가 들어간 모든 파일을 다운로드 받으면 됩니다.
https://huggingface.co/guoyww/animatediff/tree/main
다운로드받은 파일은 아래 폴더에 넣으면 됩니다. 참고로 저는 motion 이라는 폴더를 추가하고 그 속에 넣었습니다. 이렇게 서브폴더로 넣어두면 관리하기 쉽기 때문입니다.
stable-diffusion-webui\models\Lora
Motion Lora 사용법
Motion Lora를 사용하는 방법은 아주 간단합니다. 그냥 프롬프트에 일반 LoRA처럼 추가해주면 됩니다. 아래처럼요. (나머지 설정은 여기를 참고하세요.) 아래와 같이 설정하면 카메라를 왼쪽으로 끌고가는 듯한 효과가 나타납니다.
프롬프트: ((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted <lora:v2_lora_PanLeft:1>
부정적 프롬프트: CyberRealistic_Negative-neg (embedding입니다)

배경 이동속도는 <lora:v2_lora_PanLeft:1> 에서 맨마지막의 숫자 1을 변경시켜 제어할 수 있습니다. 크게하면 속도가 빨라지고, 작게하면 속도가 느려집니다. 1로 설정할 경우, 위와 같이 결함이 발생해서 아래와 같이 설정해 주었습니다.
프롬프트: ((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted <lora:v2_lora_PanLeft:0.75>

Zoom in:

Zoom out:

그런데 Zoom in과 Zoom out은 인물이 커지거나 작아지는 게 아니라 배경만 앞뒤로 움직여서 움직임 효과가 별로 나타나지 않는 것 같네요. ㅠㅠ
Image-to-Image
AnimateDiff 를 img2img에서 사용하면 구도와 이동을 어느 정도 제어할 수 있습니다. 이방법에서는 비디오의 시작 이미지와 끝나는 이미지를 지정할 수 있습니다. 그렇지만, 이 이미지와 완전히 잘 매칭되지는 않습니다. image-to-image 프로세스 자체가 원본 이미지와 출력 이미지가 달라지기 때문입니다.
AUTOMATIC1111의 img2img 페이지로 들어가 아래와 같이 설정합니다.
프롬프트: ((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted <lora:v2_lora_ZoomOut:1>
부정적 프롬프트: CyberRealistic_Negative-neg
img2img 탭의 이미지 캔버스에 시작 이미지를 업로드하고, 아래와 같이 설정합니다.
- Steps: 20
- Sampler: DPM++ 2M Karras
- CFG scale: 7
- Seed: -1
- Size: 512×512
- Denoising strength: 0.75
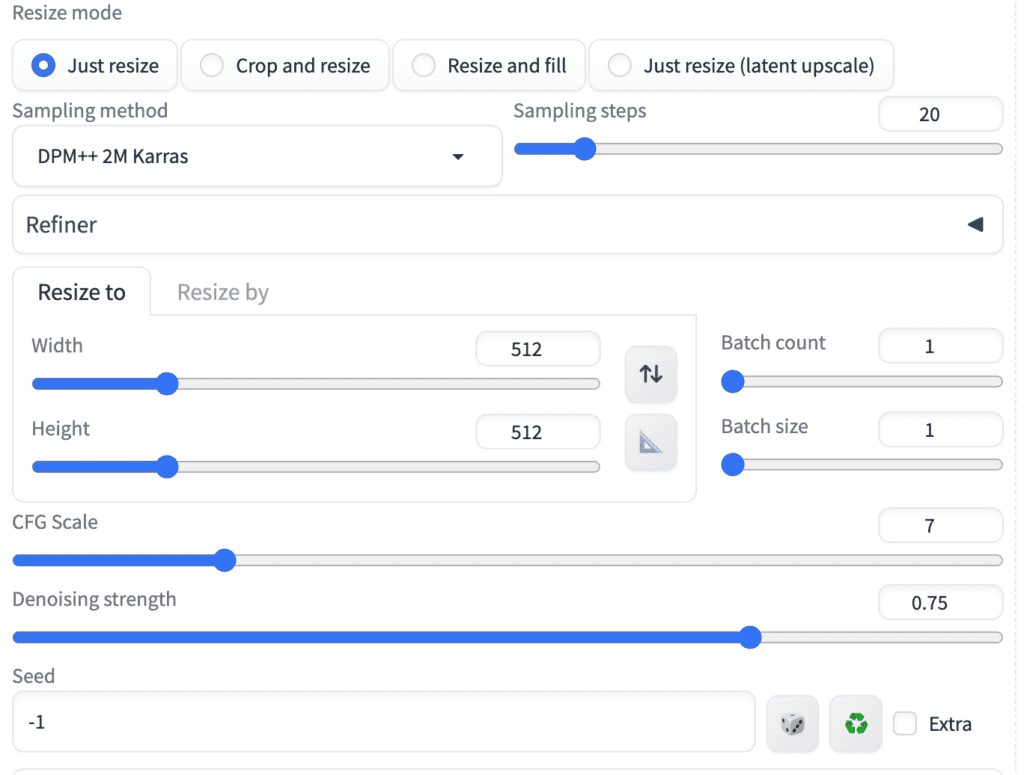
AnimateDiff 영역은 아래와 같이 설정합니다.
- Motion Module: mm_sd_v15_v2.ckpt
- Enable AnimateDiff: Yes
- Number of frames: 32
- FPS: 8
나머지는 기본 값으로 두시면 됩니다.
그리고 [optional last frame] 캔버스에 끝나는 이미지를 올려줍니다.
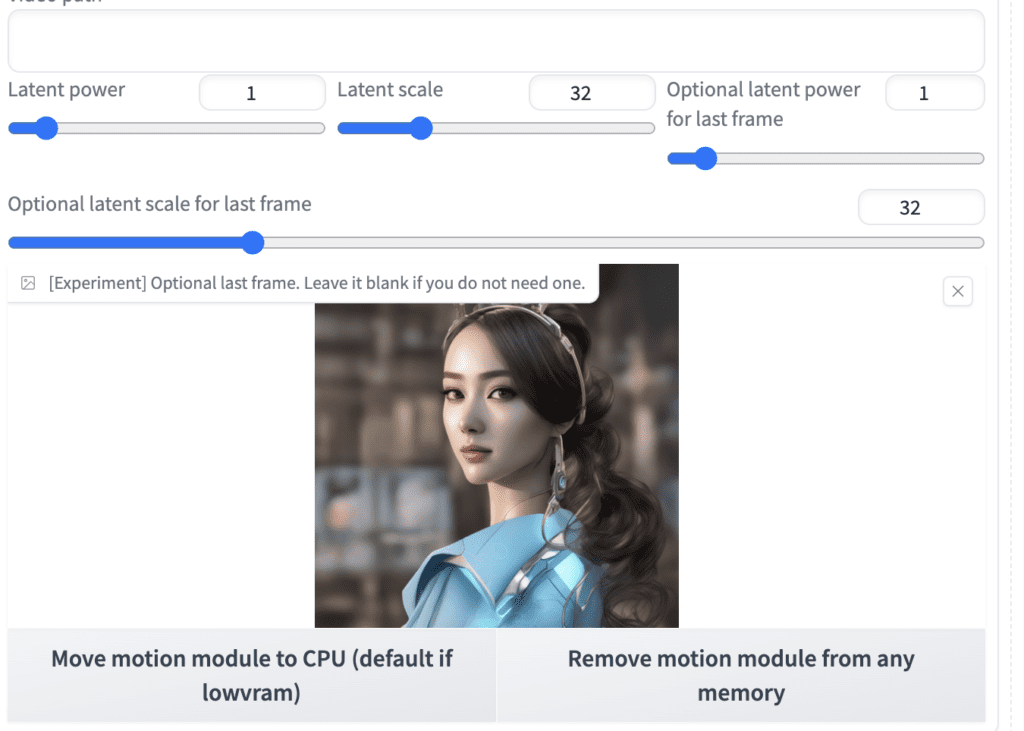
이제 [Generate] 버튼을 누르면 비디오가 생성됩니다.

AnimateDiff Prompt Travel
이제까지 생성된 AnimateDiff 비디오를 보면 어딘가 모자라다는 느낌이 듭니다. 그런데, 여러 시점에 각각 다른 프롬프트를 지정하여 움직임을 추가시킬 수 있습니다. 이러한 기능을 스테이블 디퓨전 사용자들은 Prompt Travel(프롬프트 여행)이라고 부릅니다.
Prompt Travel는 이렇게 작동합니다. 첫번째 프레임에 프롬프트1을 명시하고, 10번째 프레임에 프롬프트2를 지정했다고 가정해 보겠습니다. 1번과 10번 프레임은 어떤 이미지가 생성될 지가 결정되어 있고, 나머지 2~9번 프레임은 프레임을 내삽하는 방식으로 이루어집니다.
Prompt Travel을 사용하지 않을 경우
프롬프트: (masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl), extreme detailed,(fractal art:1.3),colorful,highest detailed
부정적 프롬프트: (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, normal quality, ((monochrome)), easynegative, badhandv4

Prompt Travel을 사용할 경우
Prompt Travel을 사용하려면 아래와 같은 포맷을 따라야 합니다.
프롬프트: (masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl), extreme detailed,(fractal art:1.3),colorful,highest detailed
0: smile
8: (arm over head:1.2)
studio lighting
첫번째 줄은 프롬프트 전치사입니다. 마지막 줄은 프롬프트 접미사입니다. 이들은 프롬프트의 시작과 끝에 공통적으로 추가됩니다. 예를 들어 0번 프레임에 대한 프롬프트는 "(masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl), extreme detailed,(fractal art:1.3),colorful,highest detailed, smile, studio lighting" 이 되는 겁니다.

HiRes. Fix를 사용한 해상도 증가
AnimateDiff 를 HiRes. Fix와 함께 사용하면 해상도를 올릴 수 있습니다. 아래와 같이 설정합니다.
- Upscaler: 4x-UltraSharp
- Hires steps: 10
- Denoising strength: 0.6
- Upscale by: 1.5

아래는 생성된 비디오입니다. 512x512를 1.5배로 확대했으니 768x768이 되었네요. 하지만, 제 컴퓨터(3070, 8GB)에서 이 걸 켜니 속도가 엄청 느려졌습니다. 메모리가 많이 부족한 모양입니다. animatediff 보다 Hires.Fix 가 3배 이상 시간을 잡아먹는 듯합니다. ㅠㅠ

AnimateDiff v3
AnimateDiff v3는 새로운 버전이 아니라 v3 버전의 모션 모듈만 갱신된 버전입니다. v3 버전을 사용하려면 그냥 모션 모듈만 다운로드 받아서 stable-diffusion-webui\extension\animatediff\model 폴더에 넣어주면 됩니다.
v3 모션 모듈은 v2와 똑 같은 방법으로 사용할 수 있습니다.
모델 : Hello Young
프롬프트: (masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl), extreme detailed,(fractal art:1.3),colorful,highest detailed
부정적 프롬프트: (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, normal quality, ((monochrome)), easynegative, badhandv4
아랜느 AnimateDiff v3로 생성한 움짤입니다.

아래는 v2 모델로 생성한 움짤입니다.

보시면 아시겠지만, v3가 v2보다 낫다는 느낌은 별로 안듭니다. 그냥 다른 움직임이 생성된다는 것 뿐입니다. 그냥 두 모델 모두 넣어두었다가 필요에 따라 사용하시면 될 것 같습니다.
SDXL용 AnimteDiff
SDXL 용 AnimateDiff도 마찬가지로 SDXL 모델에 맞는 모션모듈이 추가된 것 뿐입니다. SDXL 모션 모듈을 다운로드 받아, stable-diffusion\extensions\animatediff\model 폴더에 넣어주시면 됩니다.
SDXL용 AnimateDiff도 다른 모션 모듈과 똑같은 방법으로 사용할 수 있습니다. 다만, SDXL이 지원해주는 이미지 크기에 맞춰 사용하시면 됩니다. 또한 base 모델 뿐만 아니라, SDXL 을 기반으로 미세조정된 모델도 사용할 수 있습니다.
아래는 활용한 예입니다.
모델 : dreamshaperXL10
프롬프트: In Casey Baugh’s evocative style, art of a beautiful young girl cyborg with long brown hair, futuristic, scifi, intricate, elegant, highly detailed, majestic, Baugh’s brushwork infuses the painting with a unique combination of realism and abstraction, greg rutkowski, surreal gold filigree, broken glass, (masterpiece, sidelighting, finely detailed beautiful eyes: 1.2), hdr, realistic painting, natural skin, textured skin, closed mouth, crystal eyes, butterfly filigree, chest armor, eye makeup, robot joints, long hair moved by the wind, window facing to another world, Baugh’s distinctive style captures the essence of the girl’s enigmatic nature, inviting viewers to explore the depths of her soul, award winning art
부정적 프롬프트: ugly, deformed, noisy, blurry, low contrast, text, BadDream, 3d, cgi, render, fake, anime, open mouth, big forehead, long neck
이미지 사이즈 : 1024 x 1024
모션 모듈 : mm_sdxl_v10_beta.safetensors

AnimateDiff 속도 올리기
비디오 생성은 시간이 많이 걸립니다. 프레임들을 따로 따로 생성하려다보니 어쩔 수 없죠. 하지만, 속도를 올릴 수 있는 방법이 없는 건 아닙니다.
LCM LoRA
LCM LoRA는 스테이블 디퓨전의 속도를 올리기 위한 LoRA입니다. LCM LoRA를 사용하면 대략 3배 정도 속도가 빨라질 수 있습니다.
LCM_LoRA를 읽어보시면 LCM LoRA 모델을 설치하는 방법이 있습니다. SD 1.5 버전과 SDXL 버전이 있으니 따로 받아 두시면 됩니다. 일반 LoRA와 마찬가지로 stable-diffusion-webui\models\LoRA 폴더에 넣어주시면 됩니다.
LCM_LoRA를 사용할 때 특히 조심해야 하는 점은 샘플링 단계를 5-8 정도로 줄이고, CFG 척도를 2 정도로 낮춰 설정해야 한다는 점입니다. 아래는 예입니다.
Model: Hello Young
프롬프트 :(masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl), extreme detailed,(fractal art:1.3), colorful, highest detailed <lora:lcm-lora-sd15:1>
부정적 프롬프트 : (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, normal quality, ((monochrome)), easynegative, badhandv4
샘플러: LCM
샘플링 단계 : 7
CFG 척도: 2
아래는 AnimateDiff를 사용하지 않고 생성한 이미지 입니다. 꽤 괜찮게 나왔습니다.

아래는 Animate v3 모듈을 사용해 생성한 움짤입니다. 상당히 빠르게 생성되네요.

SDXL Turbo
SDXL Turbo 모델은 다른 SDXL 모델과 아키텍처가 동일하지만, Turbo 학습법을 통해 샘플링 단계를 줄인 모델입니다. Turbo 모델을 사용하면 대략 3배 정도 빠르게 이미지를 생성할 수 있습니다.
모델 : sd_xl_turbo_1.0_fp15
프롬프트 : In Casey Baugh’s evocative style, art of a beautiful young girl cyborg with long brown hair, futuristic, scifi, intricate, elegant, highly detailed, majestic, Baugh’s brushwork infuses the painting with a unique combination of realism and abstraction, greg rutkowski, surreal gold filigree, broken glass, (masterpiece, sidelighting, finely detailed beautiful eyes: 1.2), hdr, realistic painting, natural skin, textured skin, closed mouth, crystal eyes, butterfly filigree, chest armor, eye makeup, robot joints, long hair moved by the wind, window facing to another world, Baugh’s distinctive style captures the essence of the girl’s enigmatic nature, inviting viewers to explore the depths of her soul, award winning art
부정적 프롬프트: ugly, deformed, noisy, blurry, low contrast, text, BadDream, 3d, cgi, render, fake, anime, open mouth, big forehead, long neck
샘플러 : DPM++ SDE Karras
샘플링 단계 : 7
CFG 척도 : 2
이미지 크기: 1024x1024
모션모듈 : mm_sdxl_v10_beta.safetensors

결론
저번에 글을 썼을 때 v1.4 및 v1.5로 생성한 그림은 사실 많이 실망스러웠습니다. AI로 video를 생성하는 많은 기술들이 공통적으로 가진 문제이긴 하지만, 유달리도 프레임과 프레임 사이에 일치성이 떨어져서 번쩍거림이 심했거든요. 그런데 이번 버전에서는 상당히 좋아졌습니다. 새로나온 AnimateDiff v1.5_v2 뿐만아니라, 기존의 v1.4 및 v1.5에서도 번쩍거림이 많이 줄어들었다는 게 너무 고무적입니다.
참고로 비디오를 생성하면 1개의 비디오가 아니고 완전히 다른 2개의 비디오가 한개로 뭉쳐서 출력되는 경우가 있습니다. 다른 원인이 있을 수도 있지만, 프롬프트가 길기 때문에 발생할 수도 있습니다. 이 경우, Settings->Optimization에 들어가서 Pad prompt/negative prompt to be same length를 체크해보세요.
예전 예제
여기에 있는 예제는 v1.4 또는 v1.5 모델을 사용한 예제입니다. 그냥 참고하세요.
그랜드 캐년의 항공 사진
모델: Dreamshaper
프롬프트: aerial photo of grand canyon
CFG: 20
모션 모듈: v1.5_v2

파도
모델: Dreamshaper 5
프롬프트: A beautiful beach, waves
부정적 프롬프트: watermark, letters
CFG: 20
모션 모듈: v1.4

빨간 스웨터의 소녀
모델: Rev Animated
프롬프트: 1girl, tohsaka rin, solo, long hair, sweater, red sweater, looking at viewer, walking <lora:3DMM_V12:1>
부정적 프롬프트: disfigured, deformed, ugly
CFG Sclae : 16
LoRA: 3D rendering style
모션 모듈: v1.4

사실적인 여자 사진
모델: Realistic Vision
프롬프트: close up photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores
부정적 프롬프트: disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
CFG 척도: 20
모션 모듈 v1.5_v2

이상입니다.
===
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- Stable Diffusion - 모델에 대한 모든 것
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기
- Stable Diffusion - LoRA 모델 사용법
- Stable Diffusion - ControlNet 사용법(1)
- Stable Diffusion - ControlNet 사용법(2)
- Stable Diffusion - 하이퍼네트워크 사용법
- Stable Diffusion - AI 확대도구 사용법
- Stable Diffusion - 구역분할 프롬프트 사용법
- Stable Diffusion으로 멋진 이미지 만들기