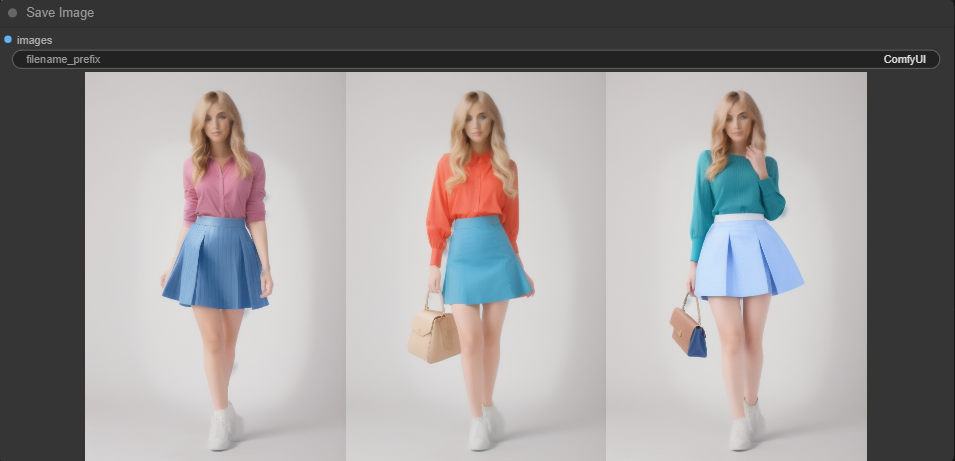
잡음제거 강도는 샘플링 단계에 들어가기 전, 이미지에 얼마나 많은 잡음을 추가할 것인지를 결정합니다. 특히 스테이블 디퓨전에서 image-to-image이지지 생성에서 공통적으로 사용되는 설정입니다. 잡음제거 강도는 0부터 1.0까지 설정할 수 있습니다. 0은 입력 이미지에 아무런 잡음을 추가하지 않는다는 뜻이고, 1.0은 입력된 이미지가 완전한 노이즈로 대체된다는 뜻입니다. 이러한 점에서 잡음제거 강도는 원 이미지를 보존하는 것과 완전히 새로운 이미지를 생성하는 것 사이의 균형이라고 생각하셔도 좋습니다. 결론적으로 잡음제거 강도를 높일 수록 이미지가 많이 변화하게 됩니다. AUTOMATIC1111에서 잡음제거 강도 image-to-image에서 잡음제거 강도 인페인트에서 잡음제거 강도 ComfyUI에서..